Del caos de datos estadísticos al control total con el vibe coding
En el entorno industrial contemporáneo, la recolección y control de datos estadísticos se ha vuelto una práctica cotidiana e indispensable. Sin embargo, acumular datos no equivale a comprenderlos; entre la medición y la toma de decisiones existe una brecha que, con frecuencia, permanece abierta por limitaciones humanas y metodológicas. La incapacidad de procesar grandes volúmenes de información de forma oportuna representa uno de los cuellos de botella más costosos en la industria moderna, ya que retrasos en el análisis se traducen directamente en ineficiencias, defectos de calidad y pérdidas económicas.
La ingeniería industrial lleva décadas apoyándose en herramientas estadísticas clásicas para el control de procesos; entre ellas, las gráficas de control desarrolladas por Walter Shewhart a principios del siglo XX siguen siendo una referencia fundamental. No obstante, la aplicación manual de estas metodologías en entornos con múltiples variables, turnos de producción y cientos de muestras diarias se convierte en una tarea agotadora y propensa al error. Es aquí donde la inteligencia artificial y el desarrollo de aplicaciones especializadas ofrecen una salida concreta y eficiente.
El problema: cuando los datos superan la capacidad humana de procesarlos
En muchas plantas industriales y laboratorios de calidad, el proceso de análisis estadístico de datos de producción sigue realizándose de manera parcialmente manual. El analista recibe archivos de hoja de cálculo con decenas o cientos de filas (cada una correspondiente a un día de medición) y múltiples columnas que representan las muestras tomadas en ese período. A partir de esa matriz de datos, debe calcular la media de cada día, la media general del proceso, la moda, la mediana y la desviación estándar; luego trazar manualmente las gráficas de control con sus límites estadísticos, e interpretar si el proceso se encuentra bajo control.
Este flujo de trabajo presenta al menos tres problemas estructurales. Inicialmente, el tiempo invertido en cálculos repetitivos es significativo; un analista puede tardar varias horas en procesar la información de una sola semana de producción. En segundo lugar, la probabilidad de errores de transcripción o de fórmula es alta, especialmente cuando los archivos se editan manualmente o se copian entre versiones diferentes de la hoja de cálculo. Adicionalmente, la interpretación subjetiva de las gráficas puede variar entre profesionales, lo que genera inconsistencias en los informes y en las decisiones derivadas de ellos.
Según Montgomery (2019), un sistema de control estadístico de procesos eficaz requiere no solo la disponibilidad de datos, sino también la capacidad de interpretarlos con rapidez y consistencia. Cuando el análisis se ralentiza, la retroalimentación al proceso pierde valor; los defectos que podrían haberse detectado y corregido en horas se prolongan durante días.
El impacto en la calidad del análisis de información
Las consecuencias de un análisis lento e inconsistente no se limitan al área de calidad; afectan transversalmente a la organización. Desde el punto de vista operativo, la detección tardía de puntos fuera de los límites de control implica que el proceso ha estado produciendo fuera de las especificaciones durante más tiempo del necesario. Esto se traduce en mayor desperdicio de materias primas, mayor tasa de reproceso y, en el peor de los casos, en productos no conformes que llegan al cliente.
Desde el punto de vista gerencial, la falta de informes oportunos dificulta la toma de decisiones basadas en datos. Los responsables de producción y calidad toman decisiones con información desactualizada, lo que mina la efectividad de las estrategias de mejora continua. Además, la variabilidad en el criterio de interpretación de las gráficas de control (según si el analista tiene experiencia en la identificación de patrones como rachas, tendencias o ciclos) genera informes que no son comparables entre sí a lo largo del tiempo.
Para empresas que operan bajo estándares de calidad internacionales como la norma ISO 9001:2015 o la IATF 16949, esta situación puede constituir una no conformidad documentable. La trazabilidad del análisis de datos del proceso es un requisito explícito de estos sistemas de gestión, y su incumplimiento puede afectar la certificación de la organización (International Organization for Standardization [ISO], 2015).
La inteligencia artificial como aliada del ingeniero industrial
La irrupción de la inteligencia artificial en los entornos productivos no es una promesa futura; es una realidad presente y accesible. Las aplicaciones de IA aplicadas al análisis de datos de proceso ofrecen ventajas concretas que van mucho más allá de la simple automatización de cálculos. En primer lugar, permiten procesar grandes volúmenes de información en segundos, eliminando el cuello de botella del análisis manual. En segundo lugar, garantizan la consistencia de los resultados, ya que la lógica de procesamiento no varía entre sesiones ni entre usuarios.
Un aspecto especialmente valioso es la capacidad de detección automática de patrones. Las gráficas de control tradicionales requieren que el analista conozca y aplique las reglas de Nelson o las reglas de Western Electric para identificar comportamientos anómalos que no consisten en un simple punto fuera de los límites de control (Wheeler & Chambers, 2010). Una aplicación bien diseñada puede implementar estas reglas de forma automática y presentar los hallazgos en un lenguaje claro y accesible, incluso para usuarios sin formación estadística avanzada.
Adicionalmente, la integración de herramientas tecnológicas en los procesos de análisis de calidad contribuye al objetivo de la transformación digital en la industria, un proceso que la Comisión Económica para América Latina y el Caribe (CEPAL) identifica como prioritario para mejorar la competitividad de las empresas de la región (CEPAL, 2021). Automatizar el análisis estadístico no reemplaza al ingeniero; lo libera de tareas rutinarias para que pueda concentrarse en el diagnóstico, la mejora y la innovación.
La aplicación web de análisis estadístico: una solución práctica y cómo utilizarla.
Frente a este panorama, se ha desarrollado una aplicación web de análisis estadístico y control de procesos diseñada específicamente para ingenieros industriales y analistas de calidad. La herramienta fue concebida para eliminar la fricción del proceso de análisis manual; su funcionamiento es sencillo, su interfaz es intuitiva con resultados inmediatos.
La aplicación recibe como entrada un archivo en formato .xlsx estructurado de la siguiente manera: cada fila representa un día de medición y cada columna corresponde a una muestra tomada en ese día. A partir de esta información, el sistema calcula automáticamente los estadísticos descriptivos fundamentales: la media de cada día, la media general del proceso, la moda, la mediana y la desviación estándar. Con estos datos construye la gráfica de control de medias, incluyendo el límite de control superior (UCL) y el límite de control inferior (LCL), calculados según el método clásico de Shewhart basado en tres desviaciones estándar respecto a la media general.
El núcleo diferenciador de la aplicación es su módulo de interpretación automática. Tras construir la gráfica, el sistema genera un resumen que responde tres preguntas clave: ¿está el proceso bajo control estadístico?, ¿existen puntos fuera de los límites de control? ¿se identifican patrones o tendencias que indiquen un comportamiento no aleatorio? Este resumen se presenta en lenguaje natural, claro y directo, acompañado de indicadores visuales que facilitan su lectura.
Paso1. Preparar el archivo de datos: Organice su información en un archivo .xlsx en el que la primera columna contenga las fechas o identificadores de los días de medición y las columnas siguientes contengan los valores de las muestras de ese día. No es necesario calcular ningún estadístico previo; la aplicación lo hace automáticamente.
Paso 2. Cargar el archivo: Acceda a la aplicación web desde cualquier navegador. En la pantalla principal encontrará un botón para cargar el archivo .xlsx. Selecciónelo desde su equipo y espere unos instantes mientras el sistema procesa la información.

Paso 3. Revisar los estadísticos: La aplicación mostrará una tabla con los resultados por día (media diaria) y los estadísticos generales del proceso: media general, moda, mediana y desviación estándar. Revise estos valores para tener una primera imagen del comportamiento del proceso.

Paso 4. Analizar la gráfica de control: Debajo de la tabla encontrará la gráfica de control de medias con la línea central (CL), el límite superior (UCL) y el límite inferior (LCL) claramente identificados. Los puntos que excedan los límites aparecerán resaltados en un color diferente para facilitar su identificación visual.

Paso 5. Leer el resumen de interpretación: Al final de la pantalla, el módulo de interpretación automática presentará las conclusiones del análisis. Si el proceso está bajo control, lo indicará de forma explícita; si existen puntos fuera de los límites o patrones identificables, los describirá con precisión y sugerirá las acciones de seguimiento correspondientes.
Esta solución representa un avance concreto en la digitalización del análisis de calidad industrial. Al reducir el tiempo de procesamiento de horas a segundos, garantizar la consistencia de los resultados y democratizar la interpretación estadística, la aplicación web de control de procesos pone al alcance de cualquier organización una herramienta que antes requería de un especialista dedicado. La tecnología ya está disponible; el siguiente paso es adoptarla.
Vibe Coding
1. ¿Qué es el vibe coding y por qué es importante?.
El vibe coding es una metodología de desarrollo de software en la que el creador describe en lenguaje natural lo que necesita construir y delega la generación del código en un modelo de inteligencia artificial generativa. El término fue acuñado por Andrej Karpathy en febrero de 2025 y define un nuevo paradigma en el que el conocimiento técnico profundo en programación deja de ser el cuello de botella para la creación de soluciones digitales (Karpathy, 2025).
Para comprender por qué el vibe coding fue la respuesta adecuada a la necesidad planteada, es necesario describir el contexto con precisión. El problema no requería un sistema de información empresarial ni una plataforma de gran escala; requería una herramienta especializada, de uso puntual, que un número reducido de analistas pudiera ejecutar directamente en su navegador sin instalaciones ni dependencias. Era exactamente el tipo de necesidad que el desarrollo de software tradicional resuelve de forma desproporcionada en costo y tiempo, pero que el vibe coding resuelve con eficiencia directa.
La aplicación resultante un archivo HTML autocontenido que recibe un archivo .xlsx con datos de medición, calcula estadísticos descriptivos, construye una gráfica de control de medias con línea central (CL), límite de control superior (UCL) e inferior (LCL), genera una tabla con semáforo de estado por día e interpreta automáticamente si el proceso está bajo control estadístico fue construida en una única jornada de trabajo, sin presupuesto en licencias y sin equipo de desarrollo. Eso es precisamente lo que hace al vibe coding importante: transforma la capacidad de resolver problemas reales con tecnología, poniéndola en manos del profesional que conoce el problema.
2. Ventajas y desventajas.
2.1 Ventajas
Velocidad de desarrollo: Lo que con un equipo de desarrollo convencional habría tomado entre una y tres semanas (levantamiento de requerimientos, diseño, desarrollo, pruebas, ajustes) se completó en aproximadamente cuatro horas de trabajo iterativo con la IA. El prototipo funcional estuvo disponible el mismo día que se identificó la necesidad.
Alineación con el problema real: Al ser el propio ingeniero industrial (quien conoce el proceso, los datos y las metodologías de control estadístico) el que construye la herramienta, el resultado está perfectamente calibrado a la necesidad. No hubo traducción del lenguaje del negocio al lenguaje técnico; ambos coincidían en la misma persona.
Costo cero en licencias: La aplicación es un único archivo HTML que usa librerías gratuitas cargadas desde CDN (SheetJS para leer Excel, Chart.js para las gráficas). No requiere servidor, base de datos ni suscripción a ningún servicio.
Distribución inmediata: Al ser un archivo autocontenido, puede compartirse por correo electrónico, en una carpeta compartida o en una intranet. Cualquier persona con un navegador puede usarla sin instalación.
Iteración sin fricción: Cada ajuste —añadir la detección de rachas, cambiar la paleta de colores, corregir el cálculo del LCL, añadir el botón de exportar resumen— se realizó mediante una nueva instrucción en lenguaje natural a la IA, sin tocar el código manualmente.
2.2 Desventajas
Código sin estructura comprensible: El HTML generado por la IA es funcional pero denso; no tiene comentarios explicativos y mezcla HTML, CSS y JavaScript en un único bloque. Si en el futuro se necesita una modificación mayor sin asistencia de IA, el mantenimiento sería difícil para alguien sin formación técnica.
Comportamiento con datos atípicos: Durante las pruebas con el archivo de datos reales, se identificaron casos que el prototipo inicial no manejaba correctamente: filas con celdas vacías, archivos con más de una hoja, o primera columna con formato de fecha no reconocido. Cada caso requirió una iteración de corrección adicional.
Ausencia de validación experta en seguridad: La aplicación no maneja datos sensibles en este caso, pero si en el futuro se añadiera envío de datos a un servidor o almacenamiento en la nube, el código generado por IA requeriría revisión de seguridad por un desarrollador profesional.
Dependencia de la IA para el mantenimiento: Las actualizaciones futuras de la herramienta dependerán de volver a usar un asistente de IA. Sin la IA, el creador no puede modificar el código por sí mismo. Esto no es un problema mientras la IA esté disponible, pero es una dependencia real que debe reconocerse.
3. Competencias para vibe coding.
La construcción de la aplicación de control estadístico de procesos mediante vibe coding no requirió saber programar, pero sí requirió un conjunto de competencias específicas que resultaron determinantes para la calidad del resultado final. Identificarlas es útil para quien quiera replicar el proceso.
Competencias disciplinares de ingeniería industrial
La competencia más crítica en todo el proyecto no fue tecnológica; fue el dominio de la metodología de control estadístico de procesos. Para construir un buen prompt, es indispensable saber con exactitud qué debe calcular la aplicación y por qué. En este caso fue necesario conocer:
- El método de Shewhart para el cálculo de UCL y LCL: UCL = X̄ + 3σ y LCL = X̄ − 3σ, donde σ es la desviación estándar de las medias diarias del proceso.
- La diferencia entre la media de cada día (x̄ subgrupo) y la media general del proceso (X̄ grande), y cuál de las dos actúa como línea central de la gráfica.
- Las reglas de detección de patrones: racha de 7 o más puntos consecutivos por encima o por debajo de la línea central; tendencia de 6 o más puntos en dirección continua ascendente o descendente.
- La interpretación correcta de un proceso “bajo control estadístico”: todos los puntos dentro de los límites y sin patrones sistemáticos identificables.
Competencias de comunicación y prompting
La segunda competencia crítica fue la capacidad de traducir ese conocimiento disciplinar en instrucciones claras, específicas y sin ambigüedad para la IA. Esto implicó:
- Descomponer la aplicación en módulos independientes y describirlos uno a uno: módulo de carga de archivo, módulo de cálculo estadístico, módulo de visualización, módulo de interpretación.
- Especificar el formato de los datos de entrada con exactitud: filas = días, columnas = muestras, primera columna = etiqueta de fecha o identificador.
- Describir el comportamiento esperado de cada elemento visual: líneas continuas vs. discontinuas, colores específicos, resaltado de puntos fuera de límites, tooltip interactivo.
- Anticipar casos extremos en el prompt inicial: ¿qué hacer si el LCL resulta negativo?, ¿qué hacer si hay celdas vacías en el archivo?
Competencias de evaluación crítica
En cada iteración fue necesario evaluar si el resultado de la IA era correcto, no solo técnicamente (¿carga el archivo sin errores?) sino metodológicamente (¿el UCL está calculado correctamente?, ¿los patrones se detectan según las reglas de Nelson?). Esta evaluación solo es posible gracias al dominio disciplinar previo. La IA puede generar código que funciona perfectamente pero que implementa un cálculo incorrecto; detectarlo requiere conocimiento del problema, no del código.
4. Técnicas fundamentales.
Herramientas principales:
Chat GPT
El asistente de IA utilizado para construir la aplicación fue Chat GPT. La elección se basó en su capacidad para manejar instrucciones largas y detalladas sin perder el hilo del contexto, su precisión en la generación de código HTML/CSS/JavaScript autocontenido y su disposición a refinar resultados a partir de descripciones del comportamiento observado, sin requerir que el usuario señale líneas de código específicas.
Lovable
Lovable es una plataforma de vibe coding especializada en la construcción de aplicaciones web completas con interfaz, lógica y base de datos, a partir de descripciones en lenguaje natural. A diferencia de herramientas como Claude o ChatGPT, que generan código para ser ejecutado externamente, Lovable construye y despliega la aplicación directamente en su entorno; el resultado no es un archivo de código sino una aplicación funcional con URL propia, lista para usar y compartir sin ninguna configuración adicional.
Su diferenciador principal frente a otras plataformas de vibe coding es la capacidad de gestionar automáticamente el stack completo: frontend, backend y base de datos en tiempo real a través de la integración con Supabase. Esto lo convierte en la opción más adecuada cuando la herramienta interna necesita almacenar datos entre sesiones, manejar múltiples usuarios o crecer en funcionalidad con el tiempo.
Librerías tecnológicas incorporadas al resultado
SheetJS (xlsx.js)
Librería JavaScript que permite leer archivos .xlsx directamente en el navegador, sin necesidad de servidor. Se cargó desde el CDN de Cloudflare. Fue el componente que hizo posible que la app procesara el archivo Excel del usuario en el lado del cliente.
Chart.js
Librería de visualización de gráficas interactivas para navegador. Se usó para construir la gráfica de control de medias con todos sus elementos: línea de medias diarias, líneas horizontales de CL/UCL/LCL, resaltado de puntos fuera de control y tooltips interactivos al pasar el cursor.
Prompting con ejemplos (few-shot)
Proporcionar ejemplos concretos de entrada y salida esperada dentro de la instrucción mejora notablemente la precisión de los resultados. Por ejemplo: “dado un archivo con estas columnas, la salida debe verse así: [ejemplo]”.
5. ¿Cómo crear una app o web desde cero sin saber código?.
1. Mapeo del proceso manual existente
Antes de escribir cualquier instrucción a la IA, se documentó con precisión el proceso que se quería automatizar: el analista recibe un archivo .xlsx, calcula manualmente la media de cada fila, calcula la media general, la desviación estándar, los límites UCL y LCL, dibuja la gráfica en Excel o en papel, interpreta visualmente si hay puntos fuera de control o patrones, y redacta el informe. Este mapeo tomó aproximadamente 30 minutos y fue el insumo más valioso del proyecto.
2. Boceto conceptual de la interfaz
Se realizó un boceto rápido en papel que mostraba la estructura de la aplicación: una zona superior de carga del archivo, una sección de tarjetas con estadísticos globales, la gráfica de control a continuación, la tabla de días debajo y el resumen de interpretación al final. Este boceto se tradujo directamente en el bloque de diseño del prompt.
3. Construcción del prompt inicial
Se redactó el prompt completo siguiendo la estructura de bloques descrita en la sección anterior. El prompt tenía aproximadamente 600 palabras y cubría con precisión cada módulo de la aplicación, los cálculos matemáticos, el diseño visual y las restricciones tecnológicas. Se envió como una sola instrucción a Claude.
4. Evaluación del primer resultado
La IA generó un archivo HTML completo en la primera respuesta. Al abrirlo en el navegador y cargarlo con un archivo de prueba, se identificaron tres problemas: los límites UCL y LCL aparecían como puntos en la gráfica en lugar de líneas horizontales continuas; los puntos fuera de control no tenían resaltado visual diferenciado; el módulo de interpretación aún no detectaba rachas ni tendencias.
5. Refinado iterativo en cinco ciclos
Primero: Corrección de la visualización de UCL y LCL como líneas horizontales discontinuas en rojo a lo largo de toda la gráfica. Instrucción: “los límites UCL y LCL deben mostrarse como líneas horizontales rojas discontinuas que cruzan toda la gráfica de izquierda a derecha, no como puntos individuales”.
Segundo: Añadir resaltado visual en rojo con tamaño mayor para los puntos cuya media diaria supere el UCL o caiga por debajo del LCL.
Tercero: Implementar la detección de rachas (7 o más puntos consecutivos en el mismo lado de la CL) y tendencias (6 o más puntos en dirección continua) en el módulo de interpretación textual.
Cuarto: Añadir la tabla con semáforo de colores: verde para días bajo control, rojo para días fuera de límites y amarillo para días que forman parte de un patrón identificado.
Quinto: Ajuste del diseño visual a la paleta de colores institucional y adición del botón para copiar el resumen al portapapeles.
6. Prueba con datos reales
Se generó un archivo de datos de prueba con 200 mediciones (40 días × 5 muestras) que incluía de forma intencional los cuatro comportamientos a detectar: proceso bajo control, tendencia ascendente, racha sostenida y puntos fuera de UCL. La aplicación los identificó correctamente en todos los casos.
6. Crear herramientas internas que optimicen procesos con vibe coding.
La aplicación de control estadístico de procesos creada mediante vibe coding es el ejemplo más directo del tipo de herramienta interna que las organizaciones necesitan y que el vibe coding hace accesible. Su valor no está en la sofisticación tecnológica, sino en la precisión con la que resuelve un problema específico de un proceso específico.
Qué automatizó la app
- El cálculo de la media de cada día (media de las muestras de cada fila del archivo Excel).
- El cálculo de la media general del proceso, la moda, la mediana y la desviación estándar de todo el conjunto de datos.
- El cálculo automático de UCL = X̄ + 3σ y LCL = X̄ − 3σ sin intervención del analista.
- La construcción de la gráfica de control de medias con todos sus elementos normativos.
- La clasificación de cada día como “bajo control” o “fuera de control” según los límites calculados.
- La detección automática de rachas, tendencias y otros patrones sistemáticos.
- La generación de un resumen textual de interpretación que un supervisor puede leer en treinta segundos.
Impacto medido sobre el proceso
Tiempo de análisis: Se redujo de entre 3 y 5 horas semanales por analista a menos de 2 minutos por análisis. El tiempo restante puede dedicarse al diagnóstico de causas y a la toma de acciones correctivas.
Consistencia de resultados: Todos los analistas que usen la misma herramienta obtendrán exactamente los mismos estadísticos y la misma interpretación para un mismo conjunto de datos; se elimina la variabilidad inter-analista.
Errores de cálculo: Al eliminar la intervención manual en los cálculos de UCL, LCL y la identificación de patrones, se eliminan también los errores asociados a fórmulas mal construidas en Excel o a criterios subjetivos de interpretación.
Trazabilidad: El resumen generado automáticamente puede copiarse directamente al informe de calidad, garantizando coherencia entre el análisis y el documento formal.
Criterios que hacían de este proceso un candidato ideal para automatización
- El proceso manual consume más de 2 horas semanales por persona: hay retorno de inversión claro en automatizarlo.
- El proceso es repetitivo y sigue siempre la misma lógica: es directamente automatizable.
- Los errores humanos en el proceso tienen consecuencias significativas: la automatización reduce el riesgo.
- El proceso no está cubierto por el software institucional existente: hay espacio para una herramienta a medida.
- El equipo que realizará el proceso no tiene formación técnica para usar software complejo: se justifica una interfaz simple y específica.
Ciclo de vida de una herramienta interna con vibe coding
- El proceso era repetitivo y seguía siempre la misma lógica matemática: misma fórmula, misma estructura de datos, mismo tipo de interpretación.
- El proceso consumía más de dos horas semanales por persona: el retorno de la automatización era inmediato y claro.
- Los errores de cálculo tenían consecuencias reales: una interpretación incorrecta del estado del proceso puede llevar a no tomar acciones correctivas necesarias o, al contrario; a intervenir innecesariamente en un proceso que está bajo control.
- El proceso no estaba cubierto por el software institucional existente: las hojas de cálculo genéricas no tienen lógica de interpretación automática ni detección de patrones.
- Los usuarios del proceso no tienen formación en programación: la interfaz debía ser tan simple que cualquier analista pudiera usarla sin capacitación técnica.
7. Diseñar una app a través de un caso práctico.
Decisión: aplicación autocontenida en un único archivo HTML
La primera decisión de diseño fue tecnológica: la aplicación debía ser un único archivo HTML que se abriera directamente en el navegador, sin instalaciones, sin servidor y sin conexión a internet. Esta decisión responde a las condiciones reales del entorno de uso: analistas en entornos industriales que no siempre tienen acceso a internet, que no pueden instalar software en equipos de producción y que necesitan una herramienta que funcione de inmediato. El vibe coding la hizo posible porque simplificó radicalmente el stack tecnológico.
Procesamiento en el lado del cliente
Dado que la aplicación no tiene servidor, todo el procesamiento de datos ocurre en el navegador del usuario mediante JavaScript. La librería SheetJS lee el archivo .xlsx directamente en memoria sin enviarlo a ningún servidor externo. Esta decisión garantizó la privacidad de los datos del proceso que en contextos industriales pueden ser información confidencial y eliminó cualquier dependencia de infraestructura externa.
Método de Shewhart con 3σ para los límites de control
El prompt se diseña en bloques: descripción general de la aplicación, especificación funcional detallada (qué calcula y cómo), especificación de la gráfica (elementos visuales, colores, interactividad), diseño de la interfaz (paleta, tipografía, estructura de paneles) y restricciones tecnológicas (un solo archivo HTML, librerías por CDN, sin backend). Cada bloque responde a una pregunta concreta que la IA necesita para generar un resultado de calidad.
Semáforo de colores en la tabla de resultados
La tabla de resultados diarios incluye una columna de estado con tres posibles valores visuales: verde (bajo control), rojo (fuera de límites) y amarillo (parte de un patrón identificado). Esta decisión responde al perfil del usuario final: un analista que necesita identificar de un vistazo los días problemáticos sin leer cada valor numérico. El lenguaje del semáforo es universalmente comprensible en entornos industriales y elimina la necesidad de interpretación adicional.
Resumen textual en lenguaje natural
El módulo más diferenciador de la aplicación es el que genera automáticamente un párrafo de interpretación en lenguaje natural. La decisión de incluirlo respondió a una necesidad real: los informes de calidad requieren texto explicativo, no solo gráficas. Al generar este texto automáticamente, la aplicación elimina la tarea de redacción del analista y garantiza que la interpretación sea consistente con los resultados calculados, sin riesgo de que el texto y los datos se contradigan.
8. Prompts y refinado de prompts para vibe coding.
Prompt inicial
Actúa como arquitecto de software, desarrollador full-stack y experto en control estadístico de procesos. Redacta en un solo párrafo cómo se debe crear una página web que permita al usuario subir un archivo Excel (.xlsx) con los datos de un producto o proceso que incluya diferentes muestras registradas por día; explica que la aplicación debe leer y validar el archivo, procesar los datos para calcular el promedio diario, la media general y los límites de control, generar automáticamente un gráfico de control de medias (X-bar chart), producir un análisis textual detallado que describa el estado del proceso y del producto indicando si está bajo control o presenta variaciones anómalas, y finalmente mostrar una tabla con el promedio de cada día; el texto debe ser claro, técnico y describir el flujo completo desde la carga del archivo hasta la visualización de los resultados en la interfaz web.
Promt refinado
Crea una aplicación web completa utilizando vibe coding en Lovable que permita al usuario subir un archivo Excel (.xlsx) con datos de un producto o proceso que contenga múltiples muestras registradas por día; la app debe procesar automáticamente el archivo, validar su estructura, calcular los promedios diarios, la media global y los límites de control estadístico, generar un gráfico de control de medias (X-bar chart) interactivo, producir un análisis textual detallado que explique el estado del proceso y del producto indicando si está bajo control o presenta variaciones anómalas, y mostrar una tabla clara con el promedio de cada día, describiendo el flujo completo desde la carga del archivo hasta la visualización de resultados en una interfaz moderna, intuitiva y lista para producción.
Promt funcional, pero muy largo para lovable
Actúa como desarrollador experto en vibe coding dentro de Lovable y crea una aplicación web moderna, minimalista e intuitiva que permita al usuario subir un archivo Excel (.xlsx) con datos de un producto o proceso que contenga diferentes muestras registradas por días (una columna de fecha o día y varias columnas de muestras). La aplicación debe procesar automáticamente el archivo, validar los datos y calcular el promedio por día, la media general del proceso y los límites de control estadísticos necesarios para construir un gráfico de control de medias (X-bar chart). La interfaz debe mostrar: 1) un módulo de carga de archivo claro y atractivo, 2) un gráfico de control interactivo donde se visualicen la línea central (CL), el límite superior (UCL) y el límite inferior (LCL), 3) una tabla organizada con el promedio de cada día, y 4) un análisis textual detallado generado automáticamente que explique el estado del proceso y del producto, indicando si está bajo control estadístico, si existen puntos fuera de los límites o patrones anormales, y proporcionando una conclusión clara y profesional. El diseño debe ser responsivo, moderno y enfocado en experiencia de usuario, mostrando el flujo completo desde la carga del archivo hasta la visualización automática de resultados en una sola página dinámica.
Promt final
Crea una aplicación web interactiva para el análisis estadístico de datos de procesos. La aplicación debe permitir al usuario cargar un archivo Excel (.xlsx) mediante un botón o función de arrastrar y soltar. El archivo tendrá la siguiente estructura: el nombre del archivo contiene el nombre de la variable a analizar (por ejemplo, temperatura, peso o tiempo de ciclo), las filas representan los días de medición y las columnas corresponden a múltiples muestras tomadas en cada día, la aplicación debe procesar los datos y calcular media de cada día ,media general del proceso ,moda ,mediana y desviación estándar, la aplicación debe generar un gráfico de control de medias (X-barra) que incluya Línea central (CL) correspondiente a la media general y Límite de control superior (UCL) e inferior (LCL) ,El gráfico debe ser visualmente claro, moderno e interactivo Además, el sistema debe generar automáticamente un resumen interpretativo en lenguaje claro que ,Indique si el proceso está bajo control estadístico ,Detecte puntos fuera de los límites de control ,Identifique patrones o tendencias, La interfaz debe ser moderna, limpia e intuitiva, e incluir, Sección de carga de archivos , Panel de resultados con estadísticas, gráfico y análisis y Mensajes de error si el archivo no cumple el formato esperado.
9. Soporte y dificultades de las apps creadas con vibe coding.
El proceso de desarrollo no fue lineal ni libre de obstáculos. A continuación se documentan las dificultades reales encontradas durante la construcción de la aplicación y las estrategias que se usaron para superarlas.
Detección incorrecta de la primera columna
En la primera versión de la aplicación, al cargar un archivo .xlsx cuya primera columna contenía fechas en formato Excel (número serial), la app las interpretaba como valores numéricos e intentaba calcular la media de esa columna junto con las muestras, produciendo resultados completamente incorrectos.
Solución: Se añadió al prompt la instrucción de detectar automáticamente si la primera columna contiene texto, fechas o valores no numéricos y, en ese caso, usarla como etiqueta del eje X y excluirla de todos los cálculos estadísticos. La corrección se implementó en el ciclo de refinado siguiente.
El LCL resultaba negativo con datos de alta variabilidad
En pruebas con un conjunto de datos de proceso con alta dispersión, el LCL calculado (X̄ − 3σ) resultaba negativo, lo que no tenía sentido físico para una variable como el diámetro de una pieza (que no puede ser negativo). La gráfica mostraba el LCL por debajo de cero, distorsionando la escala del eje Y.
Solución: Se instruyó a la IA para que, cuando el LCL calculado resultara negativo para datos intrínsecamente positivos, lo representara como cero en la gráfica pero lo indicara explícitamente en el resumen textual: “Nota: el LCL calculado es negativo; se ha establecido en 0 dado que la variable no admite valores negativos”.
Pérdida de contexto en la sesión de refinado
Después del cuarto ciclo de refinado, la IA generó una versión del código que incluía la corrección solicitada pero que revertía accidentalmente el cambio de color del semáforo implementado en el ciclo anterior. Esto se debió a que la sesión era larga y el modelo había perdido parcialmente el rastro de los cambios acumulados.
Solución: Se adoptó la práctica de guardar el código completo que funcionaba correctamente antes de pedir cada nuevo cambio. Cuando la IA revirtió un cambio anterior, se pegó el código de la versión buena junto con la instrucción del nuevo cambio, asegurando que la IA trabajara sobre la versión correcta y no sobre su recuerdo de ella.
La detección de tendencias producía falsos positivos
La primera implementación de la detección de tendencias identificaba como “tendencia ascendente” cualquier secuencia de 6 puntos en la que la mayoría fuera ascendente, no necesariamente todos consecutivos y en la misma dirección. Esto producía alertas en datos que, visualmente, no mostraban ninguna tendencia clara.
Solución: Se refinó la instrucción especificando la regla con precisión matemática: “Una tendencia se define como 6 o más puntos consecutivos en los que cada punto es estrictamente mayor que el anterior (tendencia ascendente) o estrictamente menor que el anterior (tendencia descendente). Si algún punto en la secuencia no cumple la dirección estricta, la racha se interrumpe y el conteo reinicia”.
10. Conclusiones.
La experiencia de construir una aplicación de control estadístico de procesos mediante vibe coding confirma que esta metodología no es un concepto abstracto ni una promesa futura; es una herramienta práctica, aplicable hoy, que produce resultados reales y medibles en el trabajo cotidiano del ingeniero industrial.
La conclusión más importante de este proyecto es que el vibe coding no elimina la necesidad del conocimiento disciplinar; al contrario, lo potencia. El factor que determinó la calidad del resultado no fue el conocimiento de JavaScript ni de Chart.js; fue el dominio de la metodología de control estadístico de procesos según Shewhart, el conocimiento de las reglas de Nelson para la detección de patrones y la comprensión precisa de qué significa que un proceso esté “bajo control estadístico”. Sin ese conocimiento, el prompt habría sido vago, el resultado habría sido genérico y la herramienta no habría resuelto el problema real.
La segunda conclusión relevante es de naturaleza económica y organizacional. Una herramienta que automatiza entre 3 y 5 horas de trabajo semanal por analista, elimina una categoría completa de errores de cálculo y estandariza la presentación de resultados se construyó en una jornada de trabajo, con costo cero en licencias y sin equipo de desarrollo. El retorno sobre la inversión es inmediato y evidente. Esto cambia radicalmente el análisis de viabilidad de las herramientas internas en las organizaciones: lo que antes requería justificar un proyecto de TI ahora puede iniciarse como una prueba de concepto en horas.
La tercera conclusión es una advertencia necesaria: el vibe coding tiene límites reales. La aplicación construida en este proyecto es robusta para su caso de uso específico, pero no escala a sistemas que requieran base de datos, autenticación, múltiples usuarios concurrentes o integración con sistemas institucionales. Reconocer esos límites es parte de la competencia profesional en vibe coding; saber cuándo la herramienta es suficiente y cuándo es necesario escalar a un desarrollo profesional es tan importante como saber construirla.
Finalmente, este proyecto ilustra que la competencia más valiosa en el nuevo paradigma tecnológico no es saber programar ni saber usar todas las herramientas de IA disponibles; es saber formular problemas con precisión. Quien conoce su proceso, identifica con claridad la ineficiencia, describe con exactitud la solución deseada y evalúa críticamente el resultado, obtendrá de la IA herramientas que realmente transforman su trabajo. Esa competencia es transferible a cualquier disciplina y a cualquier problema.
App segunda versión
Teniendo en cuenta las oportunidades de mejora identificadas durante la verificación de la primera versión de la aplicación, decidimos realizar mejoras, refinando el prompt.
GitMind
Desarrollo del nuevo prompt.
1) Con el anterior prompt se pide redactar el texto para que se incorpore un cuadro donde explique mejor la explicación de cómo funciona la aplicación, la introducción de usuario y poder guardar, ver y descargar los trabajos realizados.
Con el siguiente prompt, reescríbelo de manera que se reduzca lo más que pueda, sin quitar la funcionalidad que debe tener la página web, y sea más comprensible el prompt: “Crea una aplicación web interactiva para el análisis estadístico de datos de procesos”. La aplicación debe permitir al usuario cargar un archivo Excel (.xlsx) mediante un botón o función de arrastrar y soltar. El archivo tendrá la siguiente estructura: el nombre del archivo contiene el nombre de la variable a analizar (por ejemplo, temperatura, peso o tiempo de ciclo); las filas representan los días de medición y las columnas corresponden a múltiples muestras tomadas en cada día. La aplicación debe procesar los datos y calcular la media de cada día, la media general del proceso, moda, mediana y desviación estándar. La aplicación debe generar un gráfico de control de medias (X-barra) que incluya línea central (CL) correspondiente a la media general y límites de control superior (UCL) e inferior (LCL). El gráfico debe ser visualmente claro, moderno e interactivo. Además, el sistema debe generar automáticamente un resumen interpretativo en lenguaje claro que indique si el proceso está bajo control estadístico, detecte puntos fuera de los límites de control e identifique patrones o tendencias. La interfaz debe ser moderna, limpia e intuitiva, e incluir: sección de carga de archivos, panel de resultados con estadísticas, gráfico y análisis y mensajes de error si el archivo no cumple el formato esperado. ”
Resultado
Crea una aplicación web interactiva para el análisis estadístico de datos de procesos. La aplicación debe permitir al usuario cargar un archivo Excel (.xlsx) mediante un botón o función de arrastrar y soltar. El archivo tendrá la siguiente estructura: el nombre del archivo contiene el nombre de la variable a analizar (por ejemplo, temperatura, peso o tiempo de ciclo); las filas representan los días de medición y las columnas corresponden a múltiples muestras tomadas en cada día. La aplicación debe procesar los datos y calcular la media de cada día, media general del proceso, moda, mediana y desviación estándar. La aplicación debe generar un gráfico de control de medias (X-barra) que incluya línea central (CL) correspondiente a la media general y límite de control superior (UCL) e inferior (LCL). El gráfico debe ser visualmente claro, moderno e interactivo. Además, el sistema debe generar automáticamente un resumen interpretativo en lenguaje claro que indique si el proceso está bajo control estadístico, detecte puntos fuera de los límites de control e identifique patrones o tendencias. La interfaz debe ser moderna, limpia e intuitiva, e incluir: sección de carga de archivos, panel de resultados con estadísticas, gráfico y análisis y mensajes de error si el archivo no cumple el formato esperado.
2) Se redacta con nuevas funciones.
Crea una aplicación web interactiva para análisis estadístico de procesos que permita cargar archivos Excel (.xlsx) mediante botón o arrastrar y soltar. Se debe describir detalladamente que el nombre del archivo representa la variable a analizar en el proceso y los datos dados deben estar organizados: en la 1.ª columna va la fecha a analizar; en las filas deben estar las muestras tomadas de los días respectivos y las columnas deben mostrar las muestras hechas al proceso durante el día, que deben ser iguales para todos los días. Debe presentarse esta info en un cuadro explicativo.
La aplicación debe calcular automáticamente: media diaria, media general, moda, mediana y desviación estándar. También debe generar un gráfico de control X-barra y el gráfico de control por rango con línea central (CL), límite superior (UCL) y límite inferior (LCL) .
El sistema debe mostrar un resumen interpretativo en lenguaje claro, indicando si el proceso está bajo control estadístico, detectar puntos fuera de control e identificar tendencias o patrones.
La interfaz debe ser moderna e intuitiva, incluyendo en la página principal carga de archivos, panel de resultados con estadísticas, gráfico y análisis, además de mensajes de error si el archivo no cumple el formato esperado, botón de guardar archivo (solo si está registrado), eliminar (se elimina el archivo y se devuelve a la página principal) y descargar (en formato pdf). Para el registro debe pedir correo electrónico y contraseña y enviar al correo verificación para que el usuario active la cuenta. Al entrar, se encontrará con la página principal del usuario que contará con la página principal y un menú con la opción inicio, documentos, cerrar sesión. En documentos aparecerán los documentos hechos con los botones de ver, descargar, eliminar.
3) Se le solicita volver a redactar el prompt y que reduzca su extensión.
Redactar el siguiente prompt reduciendo al máximo su extensión, sin eliminar la descripción de cómo debe ser y funcionar la página web. “Crea una aplicación web interactiva para análisis estadístico de procesos que permita cargar archivos Excel (.xlsx) mediante botón o arrastrar y soltar. Debe describir detalladamente que el nombre del archivo representa la variable a analizar en el proceso y los datos dados deben estar organizados: en la 1.ª columna va la fecha a analizar; en las filas deben estar las muestras tomadas de los días respectivos y las columnas deben mostrar las muestras hechas al proceso durante el día, que deben ser iguales para todos los días. Debe presentarse esta info en un cuadro explicativo. La aplicación debe calcular automáticamente: media diaria, media general, moda, mediana y desviación estándar. También debe generar un gráfico de control X-barra con línea central (CL), límite superior (UCL) y límite inferior (LCL). El sistema debe mostrar un resumen interpretativo en lenguaje claro, indicando si el proceso está bajo control estadístico, detectar puntos fuera de control e identificar tendencias o patrones. La interfaz debe ser moderna e intuitiva, incluyendo en la página principal carga de archivos, panel de resultados con estadísticas, gráfico y análisis, además de mensajes de error si el archivo no cumple el formato esperado, botón de guardar archivo (solo si está registrado), eliminar (se elimina el archivo y se devuelve a la página principal) y descargar (en formato PDF o Word, solo si está registrado). Para el registro debe pedir correo electrónico y contraseña y enviar al correo verificación para que el usuario active la cuenta. Al entrar, se encontrará con la página principal del usuario, que contará con la página principal y un menú con las opciones inicio, documentos, cerrar sesión. En documentos aparecerán los documentos hechos con los botones de ver, descargar, eliminar”
4) Respuesta de ChatGPT
Crea una aplicación web que sea moderna e interactiva para análisis estadístico de procesos mediante archivos Excel (.xlsx) cargados por botón o arrastrar y soltar. El nombre del archivo representa la variable analizada. El Excel debe tener en la primera columna (de la fila 2 en adelante) las fechas y en las demás columnas la misma cantidad de muestras tomadas por día; esta estructura debe mostrarse en un cuadro explicativo.
La aplicación debe calcular media diaria, media general, moda, mediana, desviación estándar, además de generar gráficos de control X-barra y R con CL, UCL y LCL.
El sistema debe interpretar automáticamente los resultados, indicando si el proceso está bajo control estadístico, detectando puntos fuera de control y posibles tendencias.
La interfaz debe incluir carga de archivos, panel de estadísticas, gráficos y análisis, validación de formato, guardar, eliminar y descargar reportes en PDF o Word para usuarios registrados.
Debe incluir registro e inicio de sesión con verificación por correo electrónico y un menú con Inicio (cuenta con la página anteriormente descrita), Documentos y Cerrar sesión. En Documentos se mostrarán los análisis guardados con opciones de ver, descargar y eliminar.
5) Desarrolla más la parte de iniciar sesión, la página del usuario y la descripción de cómo debe ser el archivo.
Crea una aplicación web moderna e interactiva para análisis estadístico de procesos mediante archivos Excel (.xlsx) cargados por botón o arrastrar y soltar. El sistema debe mostrar un cuadro explicativo indicando que el nombre del archivo representa la variable del proceso a analizar y que el archivo Excel debe tener en la primera columna las fechas o días de medición. Cada fila corresponde a un día diferente y las demás columnas contienen las muestras tomadas durante ese día. Todos los días deben tener la misma cantidad de muestras para permitir el análisis estadístico y la generación correcta de los gráficos de control. Si el archivo tiene datos incompletos, columnas vacías o diferente cantidad de muestras por fila, la aplicación debe mostrar un mensaje de error claro indicando el problema.
La aplicación debe calcular automáticamente media diaria, media general, moda, mediana y desviación estándar. También debe generar gráficos de control X-barra y con línea central (CL), límite de control superior (UCL) y límite de control inferior (LCL). Además, debe crear un resumen automático en lenguaje claro indicando si el proceso está bajo control estadístico, detectando puntos fuera de control, tendencias, variaciones o patrones anormales.
La interfaz debe ser limpia, moderna e intuitiva, mostrando en la página principal la zona de carga de archivos, el panel de resultados estadísticos, los gráficos y el análisis interpretativo. También debe incluir validaciones de formato y mensajes de error fáciles de entender.
La aplicación debe contar con un sistema completo de autenticación de usuarios. El registro debe solicitar correo electrónico y contraseña, enviar un correo de verificación y activar la cuenta solo cuando el usuario confirme su email. El inicio de sesión debe permitir acceder de forma segura a los análisis guardados. Una vez autenticado, el usuario verá una página principal personalizada con un menú lateral o superior que incluya Inicio, Documentos y Cerrar sesión.
En Inicio, el usuario podrá cargar nuevos archivos, visualizar resultados y gestionar análisis. En Documentos se mostrarán todos los análisis guardados en forma de lista o tarjetas con información básica como nombre del archivo y fecha de creación, incluyendo botones para Ver, Descargar en PDF o Word y Eliminar. Las funciones de guardar y descargar solo estarán disponibles para usuarios registrados.
6) Se redactó de otra forma para que sea más entendible porque no nos convencía.
Crea una página web interactiva para análisis estadístico de procesos donde primero se debe contar con un sistema de autenticación de usuarios, de iniciar sesión y registrarse. El registro debe solicitar el correo electrónico y contraseña; al iniciar sesión, el usuario verá una página principal personalizada con un menú lateral que tiene Inicio (página principal), Documentos y Cerrar sesión.
En la página de inicio se crea una página web interactiva para análisis estadístico de procesos mediante archivos Excel (.xlsx) cargados por botón cargar. El sistema debe mostrar un cuadro explicativo indicando que el nombre del archivo representa la variable del proceso a analizar y el archivo Excel debe tener en la primera columna las fechas de medición del proceso. Cada fila corresponde a un día y las demás columnas contienen las muestras tomadas durante ese día. Si el archivo tiene datos incompletos, columnas vacías o diferente cantidad de muestras por fila, la aplicación debe mostrar un mensaje de error indicando el problema. La aplicación debe calcular media diaria, media general, moda, mediana y desviación estándar. También debe generar el gráfico de control X-barra con línea central (CL), límite de control superior (UCL) y límite de control inferior (LCL). Además, debe crear un resumen automático en lenguaje claro indicando si el proceso está bajo control estadístico, detectando puntos fuera de control, tendencias, variaciones o patrones anormales.
En Documentos se mostrarán todos los análisis guardados en forma de tarjetas con información básica como nombre del archivo y fecha de creación, incluyendo botones para Ver, Descargar en PDF y Eliminar.
7) Se le pide a ChatGPT que redacte de mejor manera y más corto el prompt.
Crea una página web interactiva para análisis estadístico de procesos donde primero se debe contar con un sistema de autenticación de usuarios, de iniciar sesión y registrarse. El registro debe solicitar el correo electrónico y contraseña; al iniciar sesión, el usuario verá una página principal personalizada con un menú lateral que tiene Inicio (página principal), Documentos y Cerrar sesión. En la página de inicio se crea una página web interactiva para análisis estadístico de procesos mediante archivos Excel (.xlsx) cargados por botón cargar. El sistema debe mostrar un cuadro explicativo indicando que el nombre del archivo representa la variable del proceso a analizar y el archivo Excel debe tener en la primera columna las fechas de medición del proceso. Cada fila corresponde a un día y las demás columnas contienen las muestras tomadas durante ese día. Si el archivo tiene datos incompletos, columnas vacías o diferente cantidad de muestras por fila, la aplicación debe mostrar un mensaje de error indicando el problema. La aplicación debe calcular media diaria, media general, moda, mediana y desviación estándar. También debe generar el gráfico de control X-barra con línea central (CL), límite de control superior (UCL) y límite de control inferior (LCL). Además, debe crear un resumen automático en lenguaje claro indicando si el proceso está bajo control estadístico, detectando puntos fuera de control, tendencias, variaciones o patrones anormales. En Documentos se mostrarán todos los análisis guardados en forma de tarjetas con información básica como nombre del archivo y fecha de creación, incluyendo botones para Ver, Descargar en PDF y Eliminar. “
8) Resultado
Crea una página web interactiva para análisis estadístico de procesos con sistema de autenticación (registro e inicio de sesión). El registro debe solicitar correo electrónico y contraseña. Tras iniciar sesión, el usuario verá una página principal personalizada con menú lateral: Inicio, Documentos y Cerrar sesión.
En Inicio, la aplicación permitirá cargar archivos Excel (.xlsx) mediante un botón. Debe mostrarse un mensaje explicativo indicando que el nombre del archivo corresponde a la variable del proceso y que la primera columna debe contener las fechas de medición; cada fila representa un día y las demás columnas las muestras tomadas ese día. Si el archivo presenta datos incompletos, columnas vacías o distinta cantidad de muestras por fila, se debe mostrar un mensaje de error claro indicando el problema.
El sistema calculará automáticamente media diaria, media general, moda, mediana y desviación estándar. También generará el gráfico de control X-barra con línea central (CL), límite superior (UCL) y límite inferior (LCL). Además, producirá un resumen en lenguaje sencillo indicando si el proceso está bajo control estadístico, detectando puntos fuera de control, tendencias o patrones anormales y un botón de guardar para que esté en documentos.
En Documentos se listarán los análisis guardados en tarjetas con nombre del archivo, fecha de creación y botones para Ver, Descargar en PDF y Eliminar.
9) ChatGPT nos dio
Crea una página web interactiva para análisis estadístico de procesos con sistema de autenticación (registro e inicio de sesión). El registro debe solicitar correo electrónico y contraseña. Tras iniciar sesión, el usuario verá una página principal personalizada con menú lateral: Inicio, Documentos y Cerrar sesión.
En Inicio, la aplicación permitirá cargar archivos Excel (.xlsx) mediante un botón. Debe mostrarse un mensaje explicativo indicando que el nombre del archivo corresponde a la variable del proceso y que la primera columna debe contener las fechas de medición; cada fila representa un día y las demás columnas las muestras tomadas ese día. Si el archivo presenta datos incompletos, columnas vacías o distinta cantidad de muestras por fila, se debe mostrar un mensaje de error claro indicando el problema.
El sistema calculará automáticamente media diaria, media general, moda, mediana y desviación estándar. También generará el gráfico de control X-barra con línea central (CL), límite superior (UCL) y límite inferior (LCL). Además, producirá un resumen en lenguaje sencillo indicando si el proceso está bajo control estadístico, detectando puntos fuera de control, tendencias o patrones anormales.
En Documentos se listarán los análisis guardados en tarjetas con nombre del archivo, fecha de creación y botones para Ver, Descargar en PDF y Eliminar.
10) Se le agregó manualmente el botón de guardar.
Crea una página web interactiva para análisis estadístico de procesos con sistema de autenticación (registro e inicio de sesión). El registro debe solicitar correo electrónico y contraseña. Tras iniciar sesión, el usuario verá una página principal personalizada con menú lateral: Inicio, Documentos y Cerrar sesión.
En Inicio, la aplicación permitirá cargar archivos Excel (.xlsx) mediante un botón. Debe mostrarse un mensaje explicativo indicando que el nombre del archivo corresponde a la variable del proceso y que la primera columna debe contener las fechas de medición; cada fila representa un día y las demás columnas las muestras tomadas ese día. Si el archivo presenta datos incompletos, columnas vacías o distinta cantidad de muestras por fila, se debe mostrar un mensaje de error claro indicando el problema.
El sistema calculará automáticamente media diaria, media general, moda, mediana y desviación estándar. También generará el gráfico de control X-barra con línea central (CL), límite superior (UCL) y límite inferior (LCL). Además, producirá un resumen en lenguaje sencillo indicando si el proceso está bajo control estadístico, detectando puntos fuera de control, tendencias o patrones anormales y tener botón de guardar para que esté en documentos.
En Documentos se listarán los análisis guardados en tarjetas con nombre del archivo, fecha de creación y botones para Ver, Descargar en PDF y Eliminar.
11) Se solicita reducir el texto a 200 palabras.
Crea una página web interactiva para análisis estadístico de procesos con autenticación de usuarios (registro e inicio de sesión con correo y contraseña). Tras ingresar, el usuario verá una página principal con menú lateral: Inicio, Documentos y Cerrar sesión.
En Inicio, el sistema permitirá cargar archivos Excel (.xlsx). Debe mostrarse un mensaje indicando que el nombre del archivo representa la variable del proceso y que la primera columna debe contener las fechas de medición; cada fila corresponde a un día y las demás columnas a las muestras de ese día. Si existen datos incompletos, columnas vacías o distinta cantidad de muestras por fila, la aplicación debe mostrar un error claro.
La app calculará media diaria, media general, moda, mediana y desviación estándar, y generará el gráfico de control X-barra con línea central (CL), límite superior (UCL) y límite inferior (LCL). También producirá un resumen en lenguaje sencillo indicando si el proceso está bajo control, detectando puntos fuera de control, tendencias o patrones anormales. Debe incluir un botón Guardar para almacenar el análisis.
En Documentos se mostrarán los análisis guardados en tarjetas con nombre del archivo, fecha de creación y opciones para Ver, Descargar en PDF y Eliminar.
Nueva versión de ControlStat
Inicio de sesión.
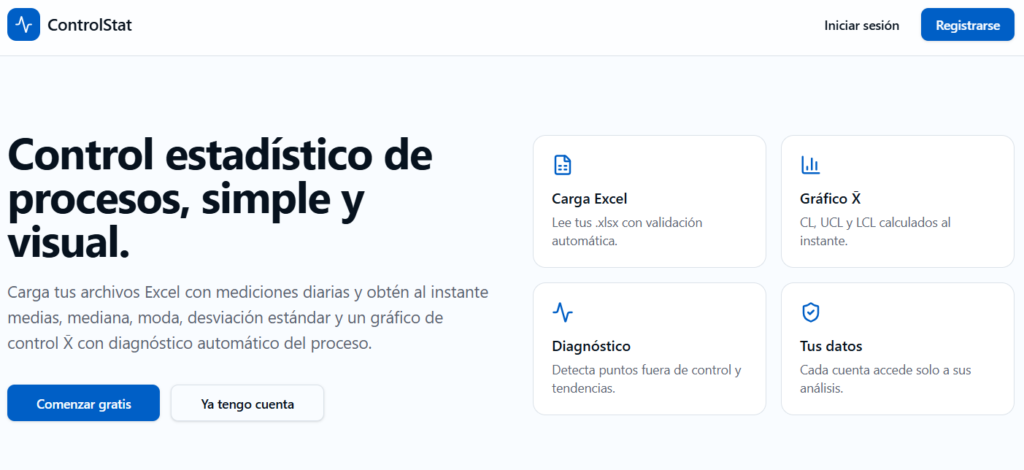
Indicaciones para el archivo
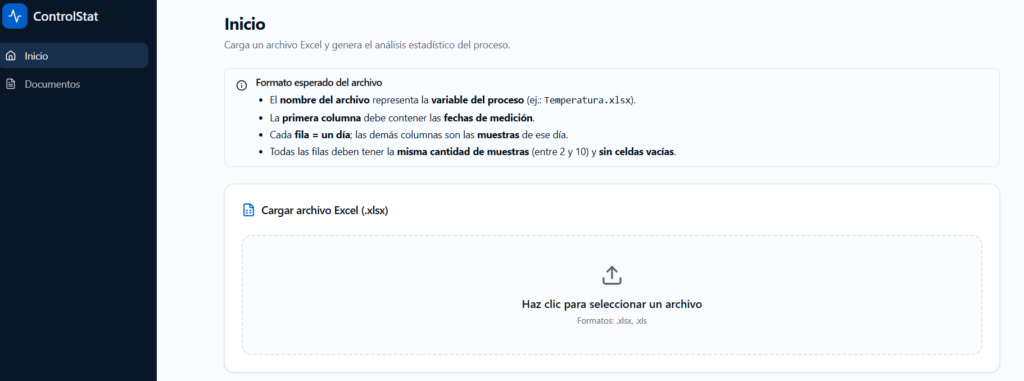
Encontrar proyectos previos
Requerimientos Funcionales
Los requerimientos funcionales describen las capacidades concretas que el sistema debe proveer. Cada requerimiento se presenta con su identificador único, nombre, descripción detallada, criterio de aceptación, nivel de prioridad (Alta / Media / Baja) y estado actual de implementación.
| ID | Nombre | Descripción | Criterio de aceptación | Prioridad | Estado |
| RF-01 | Registro de usuario | El sistema debe permitir que un nuevo usuario cree una cuenta mediante correo electrónico y contraseña. | El usuario recibe confirmación de registro y puede iniciar sesión inmediatamente. | Alta | Nuevo |
| RF-02 | Autenticación de usuario | El sistema debe permitir el inicio de sesión seguro con credenciales registradas. | Solo usuarios autenticados acceden al dashboard; credenciales incorrectas generan mensaje de error. | Alta | Nuevo |
| RF-03 | Cierre de sesión | El usuario debe poder cerrar sesión desde cualquier pantalla de la aplicación. | Al cerrar sesión, la sesión se invalida y se redirige al inicio. | Alta | Nuevo |
| RF-04 | Carga de archivo Excel | El sistema debe permitir al usuario cargar archivos .xlsx con mediciones de proceso. | Archivos válidos se procesan sin error; archivos inválidos muestran mensaje descriptivo. | Alta | Implementado |
| RF-05 | Validación del archivo | El sistema debe validar automáticamente que el archivo cargado tenga el formato y estructura requeridos. | El sistema detecta y reporta columnas faltantes, tipos de dato incorrectos o filas vacías. | Alta | Implementado |
| RF-06 | Cálculo de estadísticos descriptivos | El sistema debe calcular media, mediana, moda y desviación estándar sobre los datos cargados. | Los valores calculados coinciden con los obtenidos en una hoja de cálculo de referencia (tolerancia ±0,001). | Alta | Implementado |
| RF-07 | Generación del gráfico de control X̄ | El sistema debe generar el gráfico X̄ con la línea central (CL), límite de control superior (UCL) e inferior (LCL). | El gráfico se despliega correctamente con ejes etiquetados y valores de CL/UCL/LCL visibles. | Alta | Implementado |
| RF-08 | Diagnóstico automático del proceso | El sistema debe identificar y señalar puntos fuera de los límites de control y tendencias estadísticas relevantes. | Los puntos fuera de control se destacan visualmente; se muestra un mensaje de diagnóstico. | Alta | Implementado |
| RF-09 | Aislamiento de datos por usuario | Cada usuario debe acceder únicamente a los análisis que él mismo ha generado. | Un usuario autenticado no puede ver ni consultar los datos de otro usuario. | Alta | Implementado |
| RF-10 | Historial de análisis | El sistema debe almacenar y mostrar el historial de archivos analizados por el usuario. | El usuario puede visualizar análisis anteriores y sus resultados desde su cuenta. | Media | Nuevo |
| RF-11 | Exportación de resultados | El usuario debe poder exportar el gráfico de control y los estadísticos en formato PDF o imagen. | El archivo exportado contiene el gráfico y la tabla de estadísticos con calidad adecuada para impresión. | Media | Nuevo |
Créditos:
Autor: Valentina Rodríguez Pelayo y Cristian Eduardo Diaz Carvajal
Editor: Mg. Ing. Carlos Iván Pinzón Romero
Código: UCIAG1-8
Universidad : Universidad Central
Referencias
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., … Amodei, D. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877–1901. https://arxiv.org/abs/2005.14165
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. D. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., … Zaremba, W. (2021). Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374. https://arxiv.org/abs/2107.03374
Karpathy, A. (2025, febrero 2). There's a new kind of coding I call "vibe coding" [Publicación en X]. X (anteriormente Twitter). https://x.com/karpathy/status/1886192184808149180
Montgomery, D. C. (2019). Introduction to statistical quality control (8.a ed.). John Wiley & Sons.
OpenAI. (2023). GPT-4 technical report. arXiv preprint arXiv:2303.08774. https://arxiv.org/abs/2303.08774
Saravia, E. (2023). Prompt engineering guide. DAIR.AI. https://www.promptingguide.ai
Vercel. (2025). v0: Generative UI. Vercel Inc. https://v0.dev
Wheeler, D. J., & Chambers, D. S. (2010). Understanding statistical process control (3.a ed.). SPC Press. World Economic Forum. (2023). Future of jobs report 2023. World Economic Forum. https://www.weforum.org/reports/the-future-of-jobs-report-2023
CEPAL. (2021). Perspectivas del Comercio Internacional de América Latina y el Caribe 2021: En busca de una recuperación resiliente y sostenible. Comisión Económica para América Latina y el Caribe. https://repositorio.cepal.org/handle/11362/47472
International Organization for Standardization. (2015). ISO 9001:2015 — Sistemas de gestión de la calidad: Requisitos. ISO.
Montgomery, D. C. (2019). Introduction to statistical quality control (8.a ed.). John Wiley & Sons.
Wheeler, D. J., & Chambers, D. S. (2010). Understanding statistical process control (3.a ed.). SPC Press.