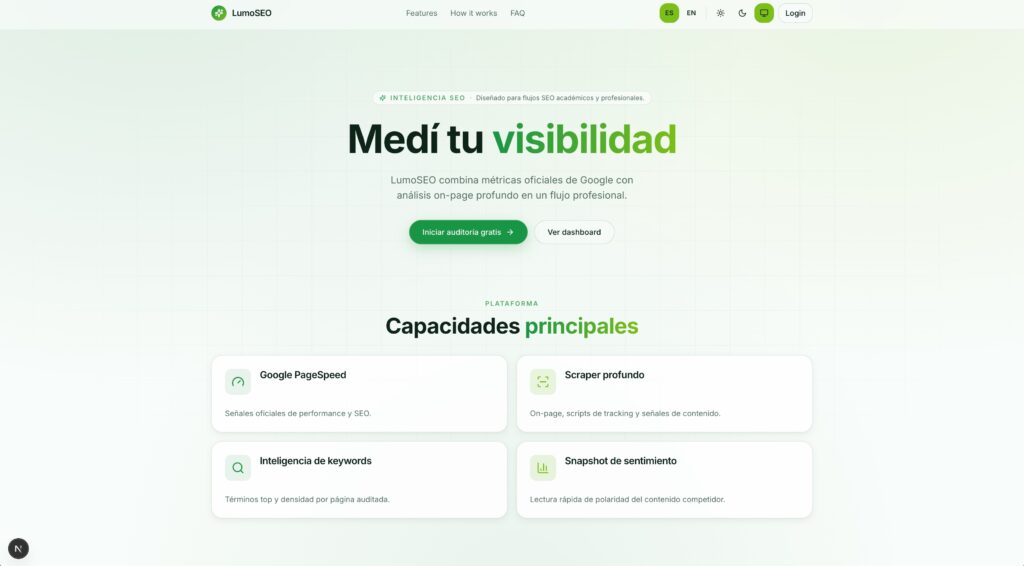
Vibe Coding con Disciplina: cómo construimos lumoSeo, una plataforma de auditoría SEO impulsada por IA
El desarrollo de software y el marketing digital están convergiendo en un punto sin precedentes. Hoy es posible construir una plataforma empresarial completa de auditoría SEO, analítica e inteligencia competitiva guiando a una IA con instrucciones en lenguaje natural, sin un equipo de ingeniería tradicional.
Esto es posible gracias al Vibe Coding, la metodología que está redefiniendo quién puede crear software y cómo se hace. Sin embargo, en este proyecto adoptamos una variante propia: vibe coding gobernado por especificaciones. En lugar de generar código a partir de prompts sueltos, cada feature pasa primero por un proceso de Spec-Driven Development (SDD) que documenta el problema, la arquitectura y los criterios de aceptación antes de que la IA escriba una sola línea.
El resultado es lemuSeo, una plataforma SaaS construida por un equipo de la Universidad Central que integra PageSpeed Insights, un motor propio de scraping con Playwright, 16 chequeos técnicos al estilo WooRank, simuladores deterministas de Google Search Console y Google Business Profile, análisis de sentimiento heurístico y un comparador competitivo multidominio — todo orquestado desde un dashboard unificado.
Este artículo documenta qué es el Vibe Coding, por qué lo combinamos con SDD, qué herramientas usamos y cómo se construyó lemuSeo desde cero.

¿Qué es el Vibe Coding y por qué nos importa?
El Vibe Coding es una metodología de desarrollo basada en la generación automática de código mediante instrucciones en lenguaje natural. En lugar de escribir cada línea, el usuario describe **qué** quiere construir y un modelo de inteligencia artificial lo materializa.
El término fue acuñado en febrero de 2025 por Andrej Karpathy, cofundador de OpenAI y exdirector de IA en Tesla (Karpathy, 2025). En noviembre de 2025, el Diccionario Collins lo eligió como palabra del año, reconociendo su impacto cultural y tecnológico (Collins Dictionary, 2025). Su frase fundacional resume la lógica: *“No es realmente programar; simplemente veo cosas, digo cosas, ejecuto cosas y copio cosas”* (Karpathy, 2025).
En este enfoque, el rol del creador cambia radicalmente. Ya no es necesario dominar React, TypeScript o Go: la función principal del operador humano es guiar, describir y refinar los resultados que produce la IA.
Su relevancia se entiende en tres dimensiones:
– Democratización del software. Profesionales de marketing, comunicación y administración pueden transformar ideas en productos digitales funcionales sin depender de un equipo de desarrollo.
– Aceleración del ciclo de creación. Lo que antes tomaba semanas de planificación técnica puede generarse, probarse y refinarse en horas.
– Cambio de paradigma. El Vibe Coding no solo cambia *cómo* se hace el software; también cambia *quién* puede hacerlo.
Según Y Combinator, en marzo de 2025 el 25 % de sus startups ya tenía bases de código generadas casi por completo mediante IA. Garry Tan, CEO de la aceleradora, afirmó que diez ingenieros pueden realizar hoy el trabajo que antes requería equipos de hasta cien personas (Tan, 2025).
Nuestro giro: Vibe Coding + Spec-Driven Development
Construir lemuSeo no es lo mismo que construir un MVP descartable. Hay un contrato de datos entre el frontend y el motor de scraping, hay decisiones de arquitectura que afectan el costo de hosting, y hay vulnerabilidades de seguridad que un MVP improvisado suele dejar abiertas (SSRF en el endpoint de scraping es un caso paradigmático).
¿Qué es OpenSpec?
OpenSpec es un sistema abierto de Spec-Driven Development diseñado para trabajar con agentes de IA generadores de código (Claude Code, Cursor, Copilot, Gemini, etc.). Funciona como una capa de control sobre el repositorio: cada cambio significativo se modela como un *change* con tres artefactos mínimos —`proposal.md` (qué y por qué), `design.md` (cómo) y `tasks.md` (pasos verificables)— que se validan antes de tocar código y se archivan en `openspec/specs/` cuando se cierran. La spec resultante se vuelve la fuente de verdad sobre el comportamiento observable del sistema.
Para una IA, OpenSpec resuelve un problema concreto: el modelo nunca tiene que adivinar qué debería hacer el sistema. La spec se le pasa como contexto verificable y el código generado se contrasta contra ella. Para el equipo humano, OpenSpec resuelve otro problema: cada decisión arquitectónica queda trazable, fechada y revisable como un commit más del repo.
El flujo en lemuSeo es:
1. Una spec describe el contrato observable del sistema (`openspec/specs/audit-contract/spec.md`).
2. Un change propone una modificación: `proposal.md` (qué y por qué), `design.md` (cómo), `tasks.md` (pasos verificables).
3. Recién entonces la IA genera el código, contra ese contrato.
4. Al archivar el change, la spec queda actualizada y el cambio queda trazable.
Esto soluciona el problema central del Vibe Coding puro: el código generado por IA puede ser difícil de mantener si no hay una fuente de verdad sobre qué debería hacer el sistema. Con SDD esa fuente de verdad existe y vive en el repositorio.
Ventajas del enfoque
– Velocidad de prototipado real. La arquitectura completa de lemuSeo — autenticación con Clerk, dashboard internacionalizado, motor de scraping en Go, módulos SEO y comparador competitivo — se generó en una fracción del tiempo que hubiera requerido un equipo tradicional.
– Accesibilidad técnica. Ningún integrante del equipo necesitó dominar Next.js 15, TypeScript, Tailwind o Go/Fiber para obtener un resultado de nivel profesional. El conocimiento del negocio fue suficiente para guiar a la IA.
– Iteración sin fricción. Cuando un módulo no se comportaba como se esperaba, en lugar de depurar código se ajustaba el prompt o se refinaba la spec.
– Trazabilidad auditable. Cada feature tiene su propio change archivado (`web-foundation`, `ui-foundation`, `woorank-checker`, `gsc-simulator`, `competitor-compare`) con proposal, design y tasks.
Desventajas que asumimos
– Calidad y mantenibilidad del código. El código generado por IA requiere revisión técnica posterior. Por eso incorporamos una capa de auditoría OWASP (más sobre esto al final del artículo).
– Vulnerabilidades de seguridad. La rapidez puede llevar a omitir controles críticos. Aceptar código sin revisión expone datos sensibles, y nuestro endpoint de scraping es un blanco SSRF natural si no se valida la URL de entrada.
– Limitaciones en lógica compleja. El Vibe Coding es muy efectivo para prototipos, MVPs y plataformas de gestión. Sistemas con lógica de negocio profunda aún requieren supervisión técnica.
– Dependencia del modelo de IA. Los resultados dependen directamente del modelo utilizado y de su disponibilidad.

El ecosistema de herramientas
El ecosistema de Vibe Coding en 2025-2026 se organiza por perfil de usuario y tipo de proyecto.
Plataformas full-stack (sin código o bajo código)
Ideales para construir aplicaciones completas desde cero usando prompts en lenguaje natural:
– Lovable.dev. Una de las más amigables para perfiles no técnicos. Permite construir y desplegar aplicaciones completas, conectar repositorios de GitHub y trabajar con bases de datos mediante Supabase. En 2025 alcanzó una valoración de 6.600 millones de dólares (Lovable, 2025).
– Bolt.new. Creada por StackBlitz, permite importar diseños de Figma y convertirlos directamente en código. Incluye un IDE en el navegador e integración con GitHub y Supabase.
– Replit. Combina entorno de desarrollo y despliegue en una sola interfaz. Ideal para aplicaciones funcionales con persistencia de datos listas para producción.
– Vercel v0. Evolucionó de generador de UI a plataforma completa de desarrollo frontend, con foco en calidad del código y modo de diseño visual.
Editores de código con IA (para perfiles técnicos)
– Cursor. Uno de los pioneros, con más de un millón de usuarios en 2025 (Anysphere, 2025). Permite cambios directos en archivos del proyecto con soporte para servidores MCP.
– Windsurf. Fork de VS Code con experiencia de usuario optimizada y previsualización integrada.
– GitHub Copilot. Integrado en Visual Studio Code y JetBrains, ofrece sugerencias contextuales, chat conversacional y modo agente para tareas multi-paso.
– Claude Code. Herramienta CLI de Anthropic. Lee y comprende la base de código completa al inicio de cada sesión y puede modificar docenas de archivos simultáneamente.
Las herramientas que efectivamente usamos en lemuSeo
| Herramienta | Rol en el proyecto |
| Vercel | Despliegue serverless del dashboard Next.js |
| Render / Railway | Despliegue del scraper Go en contenedor con Chromium |
| Claude Code | Generación y refactor del código del monorepo, con orquestación SDD |
| OpenSpec | Gobernanza spec-first: proposal, design, tasks por cada feature |
| Supabase (MCP) | Persistencia, autenticación y RLS para snapshots de auditoría |
| Clerk | Autenticación OAuth (Google, Microsoft) y gestión de sesiones |
La decisión de usar SDD encima del Vibe Coding nos obligó a invertir tiempo en proposals y designs antes de tocar código. A cambio, los seis cambios archivados hasta hoy tienen contratos verificables y se integraron sin retrabajos significativos.
La arquitectura: dos agentes, un contrato
lumoSeo es un monorepo híbrido con dos servicios que se comunican por un contrato HTTP versionado:
“`
┌──────────────────────────────────────────────────────────────┐
│ dashboard-web (Next.js 15 App Router + Supabase + Clerk) │
│ ─ Orquesta requests │
│ ─ Llama PageSpeed Insights API (público, server-side) │
│ ─ Llama scraper-api (POST /api/audit) │
│ ─ Persiste histórico en Supabase (seo_snapshots) │
└────────┬───────────────────────────────────┬─────────────────┘
│ │
▼ ▼
┌────────────────────────┐ ┌────────────────────────────┐
│ Google PageSpeed API │ │ scraper-api (Go + Fiber) │
│ (público, free tier) │ │ ─ Playwright headless │
└────────────────────────┘ │ ─ 16 chequeos WooRank │
│ ─ GTM/GA4/Ads sniffer │
│ ─ Densidad de keywords │
│ ─ Sentimiento heurístico │
└────────────────────────────┘
“`
Una decisión consciente: sin Service Accounts de Google
Las plataformas comerciales se apoyan en cuentas de servicio para hablar con las APIs privadas de GA4, Google Ads o Google Business Profile. Esa ruta tiene fricciones operativas y, en contextos académicos, suele estar bloqueada. Por eso elegimos un camino distinto:
– PageSpeed Insights lo consumimos con su endpoint público (no requiere autenticación).
– GTM, GA4 y Google Ads los detectamos por sniffing del HTML renderizado por Playwright, sin tocar APIs privadas.
– Google Search Console y Google Business Profile los simulamos de forma determinista a partir de un PRNG sembrado con el dominio. Los datos no son reales, pero son consistentes entre sesiones y útiles para demostrar el flujo de UX y reportería.
Esta decisión está documentada en `AGENTS.md` y es probablemente el diferenciador más honesto del proyecto frente a otras plataformas que prometen integraciones que en la práctica nunca se autorizan.
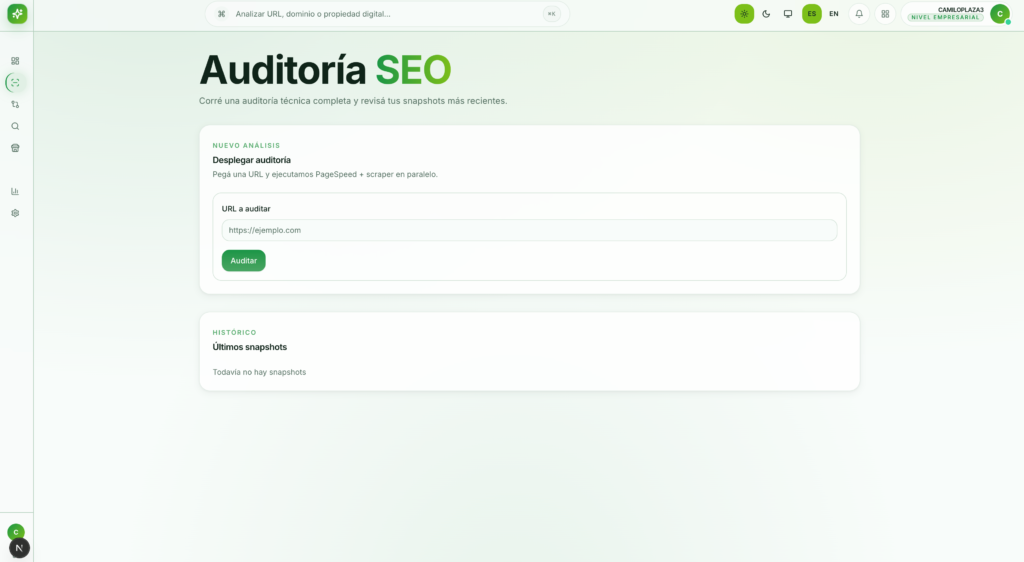
Los módulos de lemuSeo en detalle
Auditoría on-page con scraping real
El corazón funcional del producto. El usuario ingresa una URL y `scraper-api` ejecuta:
– Renderizado headless con Playwright (necesario para SPAs y para detectar scripts inyectados en runtime).
– Extracción on-page: título, meta description, jerarquía H1-H6, cobertura de atributos `alt` en imágenes, longitud de contenido.
– Detección de tracking: GTM, GA4 y Google Ads identificados por sus IDs en el DOM renderizado y en el `dataLayer`.
– Densidad de keywords: cálculo de los términos más relevantes con sus frecuencias relativas.
– Análisis de sentimiento: clasificación ternaria (positivo / neutral / negativo) mediante heurística local determinista — sin LLMs, sin costos por consulta, sin variabilidad entre ejecuciones.
El resultado se devuelve como un JSON con un contrato fijo (`audit-contract` v0.2.0) y se persiste en la tabla `seo_snapshots` de Supabase.
16 chequeos técnicos al estilo WooRank
El change `woorank-checker` agregó un módulo de auditoría técnica con 16 chequeos agrupados por categoría:
– Contenido: presencia y largo de title, meta description, H1, ratio texto/HTML.
– Mobile-friendly: viewport meta, fuentes legibles, ausencia de Flash.
– Tecnología: detección de HTTPS, HSTS, compresión, favicon.
– Indexación: robots.txt, sitemap.xml, canonical, Open Graph.
Cada chequeo aporta a un score agregado 0-100, presentado en la UI con un ring SVG por categoría dentro de la pestaña “WooRank” en `/audit/[snapshotId]`. La lógica de scoring vive en Go con tests unitarios (`woorank_test.go`, `sentiment_test.go`, `tracking_test.go`), lo cual es relevante: a pesar de haberse generado con asistencia de IA, el código está cubierto por tests reproducibles.
Search Console simulado, pero coherente
El change `gsc-simulator` resuelve un problema concreto: no podemos conectarnos al GSC del usuario sin Service Accounts. La solución fue construir un simulador con cinco rutas (`/gsc/performance`, `/gsc/pages`, `/gsc/queries`, `/gsc/devices`, `/gsc/countries`) y un generador determinista basado en un PRNG sembrado por dominio.
¿Por qué importa esto? Porque los datos son estables: el dominio `niixer.com` siempre arroja la misma serie temporal de clics e impresiones, lo que permite demostrar el flujo de UX y reportería sin invertir en datos sintéticos aleatorios que confundirían al usuario. Las propiedades disponibles son las que ya estén en `seo_snapshots`, así que GSC se siente como una extensión natural del flujo de auditoría.
La visualización usa SVG nativo: series de tiempo con tooltips, donuts por dispositivo y mapas de calor por país. Cero dependencias de librerías de gráficos pesadas.
Comparador competitivo on-demand
El change `competitor-compare` permite auditar hasta cuatro dominios simultáneamente reutilizando `runFullAudit`. Los resultados se muestran en:
– Tabla con heatmap por métrica, con codificación de color por percentil.
– Radar SVG de seis ejes que cruza Title Quality, Meta Quality, H1, Alt Coverage, WooRank Score y Sentiment Polarity.
– Keyword gap: lista de términos en los que un competidor aparece y el dominio propio no, ordenados por densidad.
Este módulo no persiste datos: es on-demand, ideal para análisis ad-hoc sin contaminar el histórico del usuario.
Dashboard con i18n y theming
El change `web-foundation` estableció las bases del frontend:
– Next.js 15 App Router con segmentación `[locale]/(auth)` y `[locale]/(protected)`.
– next-intl para internacionalización con archivos de mensajes versionados.
– next-themes para modo claro/oscuro persistente.
– Sitemap, robots y manifest generados dinámicamente.
– Metadatos SEO con tests unitarios (`metadata.test.ts`) — sí, hicimos SEO de la plataforma de SEO.
El change `ui-foundation` consolidó la capa visual con 16 primitivos de Shadcn/ui, lucide-react, sonner para toasts y react-hook-form + zod para formularios validados. El `ThemeToggle` y el `LocaleSwitcher` se migraron a `ToggleGroup` para coherencia visual.
Cómo se construyó: el flujo SDD real
A diferencia de un proyecto puro de Vibe Coding, cada feature de lemuSeo pasó por seis fases formales:
| Fase | Comando | Artefacto |
| Iniciar feature | `/sdd-init <feature>` | `openspec/changes/<feature>/` |
| Product spec | `/sdd-prd <feature>` | `proposal.md` |
| Arquitectura | `/sdd-arch <feature>` | design.md` |
| Plan de tareas | `/sdd-plan <feature>` | `tasks.md` |
| Review | `/sdd-review <feature>` | `validate` + archive |
| Estado | `/sdd-status <feature>` | `openspec list` |
Regla dura del proyecto: ningún pull request de feature se mergea sin su `openspec/changes/<feature>/` archivado en `openspec/specs/`.
Estructura de los prompts utilizados
Los prompts en este proyecto siguieron una estructura de cinco elementos consistente con las mejores prácticas del Vibe Coding profesional:
1. Contexto del producto. Descripción del tipo de plataforma, su propósito y el perfil del operador.
2. Stack tecnológico. Especificación explícita: Next.js 15 App Router, TypeScript estricto, Tailwind, Shadcn/ui, Supabase, Go 1.23 + Fiber + Playwright.
3. Contrato a respetar. El JSON de respuesta del scraper, definido en `audit-contract/spec.md`, es citado en cada prompt que toca esa interfaz.
4. Módulos requeridos. Lista numerada y detallada de funcionalidades.
5. Arquitectura de carpetas. Estructura de directorios esperada para garantizar modularidad.
La diferencia con un flujo de Vibe Coding clásico es el paso 3: el contrato. Al referenciar explícitamente la spec, la IA genera código que respeta el contrato observable del sistema, lo que reduce drásticamente los desajustes entre frontend y backend.
Lecciones del proceso
El caso de lemuSeo deja varias lecciones operativas para equipos que quieran construir plataformas empresariales con Vibe Coding:
1. El conocimiento del dominio pesa más que el conocimiento técnico. El equipo no necesitó saber programar para definir una arquitectura *enterprise*. Sí necesitó saber qué métricas necesita un equipo de marketing digital, qué chequeos hace un especialista SEO al revisar un sitio, y qué decisiones puede tomar un CMO mirando un dashboard.
2. El prompt es solo el principio: la spec es la garantía. Los prompts producen código; las specs producen sistemas. Sin SDD, el código generado se vuelve difícil de mantener apenas crece.
3. Honestidad sobre lo que es real y lo que es simulado. Diferenciar PageSpeed real, scraping real, y simuladores deterministas es lo que separa una demo de un producto creíble.
4. La seguridad no es opcional, aunque la IA tienda a omitirla. Por eso incorporamos una capa de auditoría OWASP propia.
AUDITORIA A LUMOSEO
Reconocimiento de red
El siguiente apartado detalla la fase de Reconocimiento de Red, una etapa activa y crucial para mapear la infraestructura del objetivo antes de cualquier análisis profundo. Para lograrlo, se aplicará una metodología técnica que incluye el uso de Ping para comprobar la conectividad y resolución DNS, Tracert para analizar el enrutamiento de los paquetes, y Nmap para descubrir los puertos y servicios expuestos. Asimismo, en estricto cumplimiento con las mejores prácticas de auditoría ética y trazabilidad, se documentará primero la dirección IP pública desde la cual se ejecutan estas pruebas, garantizando un entorno transparente y controlado.
IP PUBLICA DE AUDITORIA:
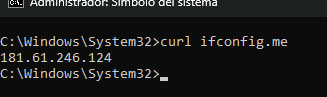
En esta captura se documenta la verificación de la dirección IP pública desde la cual se realizan las pruebas. Registrar este origen es una práctica esencial en hacking ético para garantizar la transparencia del ejercicio, permitiendo que los administradores del servidor identifiquen el tráfico de la auditoría en sus registros de seguridad (logs) y lo diferencien de posibles amenazas reales.
PING:
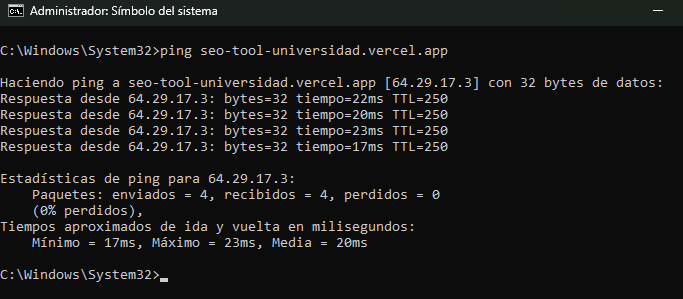
Al ejecutar una prueba de conectividad (Ping) contra el dominio de la aplicación generada por IA, los resultados revelan que este resuelve mediante un alias (CNAME) hacia la infraestructura de Vercel (cname.vercel-dns.com, IP 76.76.21.21). A diferencia de muchos servidores tradicionales que bloquean estas peticiones por seguridad, esta arquitectura Serverless (Edge Network) permite el tráfico ICMP, mostrando una conexión estable, sin pérdida de paquetes y con baja latencia. Desde una perspectiva de ciberseguridad, este comportamiento nos indica que la protección a nivel de red y firewall perimetral está fuertemente gestionada por el proveedor en la nube. Por consiguiente, a la hora de auditar este tipo de aplicaciones creadas con inteligencia artificial, el esfuerzo no debe centrarse en el escaneo de puertos tradicionales, sino en auditar de lleno la capa de aplicación (Capa 7), buscando vulnerabilidades lógicas, de validación o fallos en el código fuente generado
TRACERT:
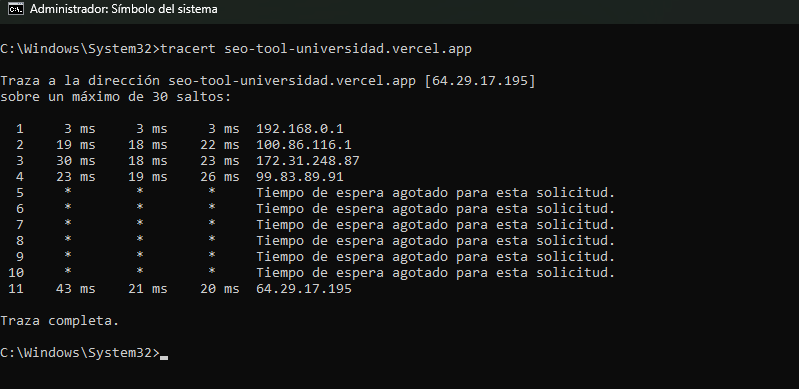
El comando tracert (Traceroute) se ejecuta con el fin de mapear el camino exacto y medir los tiempos de respuesta (latencia) que experimenta un paquete de datos desde el equipo del auditor hasta el servidor de destino (en este caso, la infraestructura de Vercel). Su utilidad en una auditoría radica en que permite identificar visualmente cada enrutador intermedio, detectar problemas de conectividad y descubrir dónde se encuentran los sistemas de filtrado o firewalls perimetrales.
A partir de la traza obtenida en la imagen, el significado técnico de los saltos seleccionados es el siguiente:
- Salto 1 (Puerta de Enlace Local / Gateway): Es el primer paso del paquete fuera del equipo. Corresponde a la dirección IP privada del router local o módem físico desde donde se hace la prueba. Registrar un tiempo bajo aquí confirma que la red interna del auditor está funcionando correctamente.
- Saltos 2, 3 y 4 (Red Troncal del ISP Local): Este bloque de saltos representa el recorrido de los datos dentro de la infraestructura interna del Proveedor de Servicios de Internet (ISP) del auditor. El Salto 2 es el nodo de acceso residencial o metropolitano más cercano, mientras que los Saltos 3 y 4 corresponden a enrutadores de transporte masivo encargados de interconectar y dirigir el tráfico hacia los nodos de salida nacional o internacional.
- Salto 11 (Perímetro de Seguridad / Entrada a Vercel): Este salto marca la frontera final de la traza. Representa el punto exacto donde los paquetes llegan a la red global de entrega de contenido (CDN) de Vercel. La presencia de asteriscos (
* * *) o el fin de la respuesta en este punto indica que se ha alcanzado el firewall perimetral del proveedor, el cual descarta los paquetes de rastreo de forma intencional para proteger y ocultar la topología interna del servidor contra el reconocimiento malicioso.
NMAP:
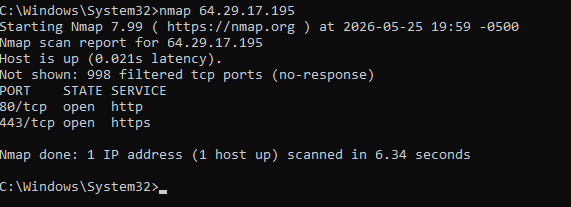
El comando nmap (Network Mapper) se ejecuta con el fin de descubrir los puertos lógicos abiertos en el servidor de destino y los servicios que se están ejecutando en ellos. Esta prueba es fundamental para determinar la “superficie de ataque” a nivel de red, identificando posibles vías de entrada no autorizadas o servicios vulnerables expuestos.
Al analizar la captura de pantalla del escaneo realizado a la IP pública del servidor (76.76.21.21), se extraen las siguientes conclusiones técnicas:
- Puerto 80/tcp (Open – HTTP): Este puerto se encuentra abierto y ejecuta el servicio web estándar sin cifrar. En infraestructuras modernas como la de Vercel, su única función es recibir las peticiones iniciales de los usuarios para redirigirlas automáticamente hacia una conexión segura.
- Puerto 443/tcp (Open – HTTPS): Es el puerto principal de la aplicación. Se encuentra abierto y configurado para gestionar el tráfico web cifrado mediante protocolos SSL/TLS, garantizando la confidencialidad e integridad de los datos en tránsito entre el usuario y la plataforma.
- Puertos Filtrados (Filtered): El reporte indica que el resto de los puertos comunes escaneados se encuentran bajo el estado de “filtrados”. Esto significa que un dispositivo de protección perimetral (un firewall adaptativo o balanceador de carga de Vercel) intercepta las sondas de Nmap y descarta los paquetes sin responder.
DNS, WHO IS, CERTIFICADOS
A continuación se va realizar unas pruebas de conectividad en donde vamos a visualizar a qué
DNS se encuentra vinculado nuestra página web, para eso utilizaremos dentro del CMD un
comando llamado “nslookup” en donde se encarga de diagnosticar y solucionar problemas de
DNS vinculados a una dirección IP.
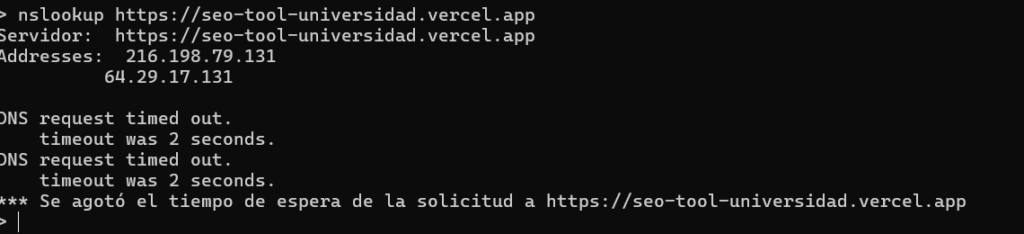
Una vez utilizado el comando nos despliega dos direcciones IP de nuestra pagina desplegada en Vercel, los cuales son:
- 216.198.79.131
- 64.29.17.131
A partir de esto nos vamos a la herramienta de WhoIs, en donde funciona como un
protocolo dentro de internet y base de datos pública sobre los registros DNS, direcciones, entre
otras. Una vez sabiendo esto procederemos a ingresar a una página web que tenga este tipo de
herramienta a conseguir la información de nuestra página web a profundidad para saber cómo
está estructurada nuestra página con el dominio que posee.
Ingresamos una de las direcciones IP’s y nos depliegara esto:
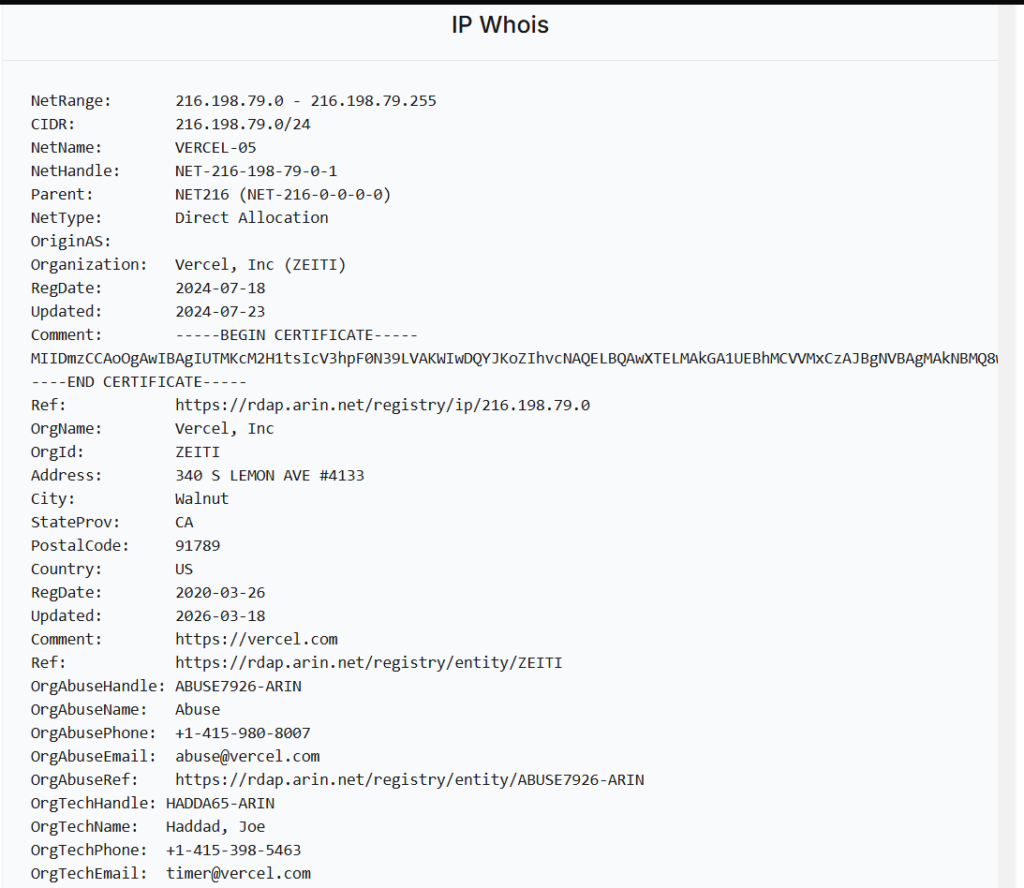
En donde tenemos información como la ultima actualización del certificado de la pagina en general de Vercel, como las fechas que se actualizaron los certificados SSL dentro de la pagina, en donde se encuentra la sede principal de la página, entre otros
Ahora procederemos a revisar los registros TXT, MX y A, para esto utilizaremos la herramienta “DNS Checker” en donde miraremos como estaría distribuidos los registros de subdominios de la página Vercel.
Primero revisamos los registros de tipo A:
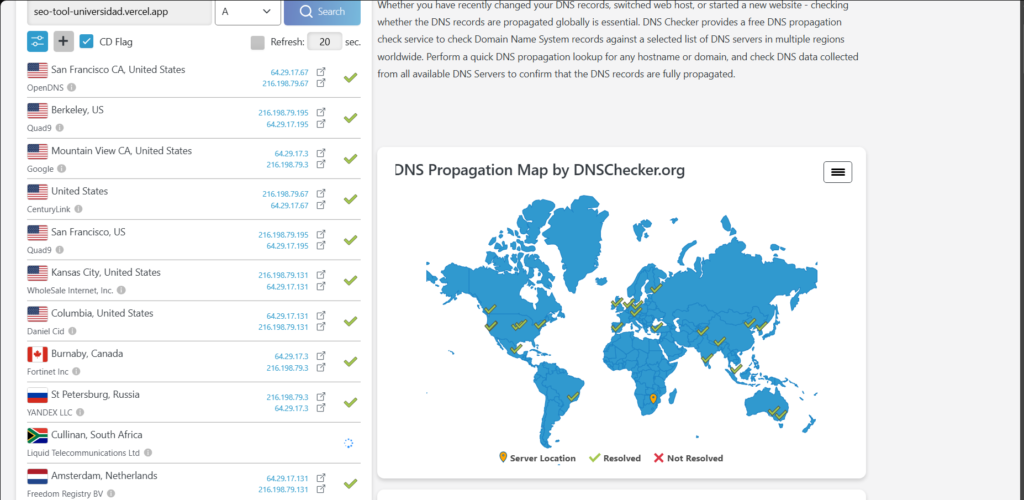
En donde podemos concluir que el sitio cuenta con protección perimetral contra ataques de denegación de servicio (DDoS), ya que el tráfico malicioso se distribuye y absorbe entre múltiples servidores globales en lugar de saturar un único servidor central.
Luego los registros de tipo MX:
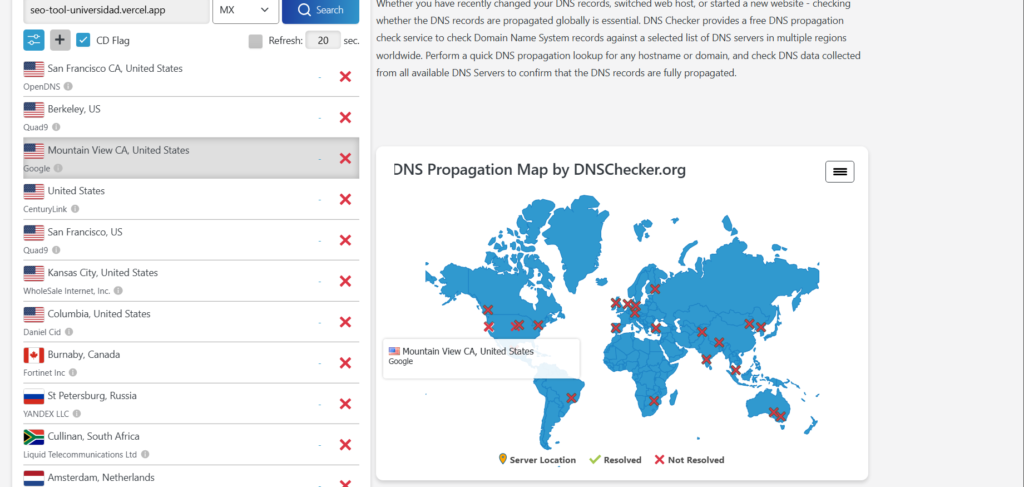
Al no existir registros MX, este subdominio específico no puede recibir correos electrónicos.
Por ultimo, los registros de tipo TXT:
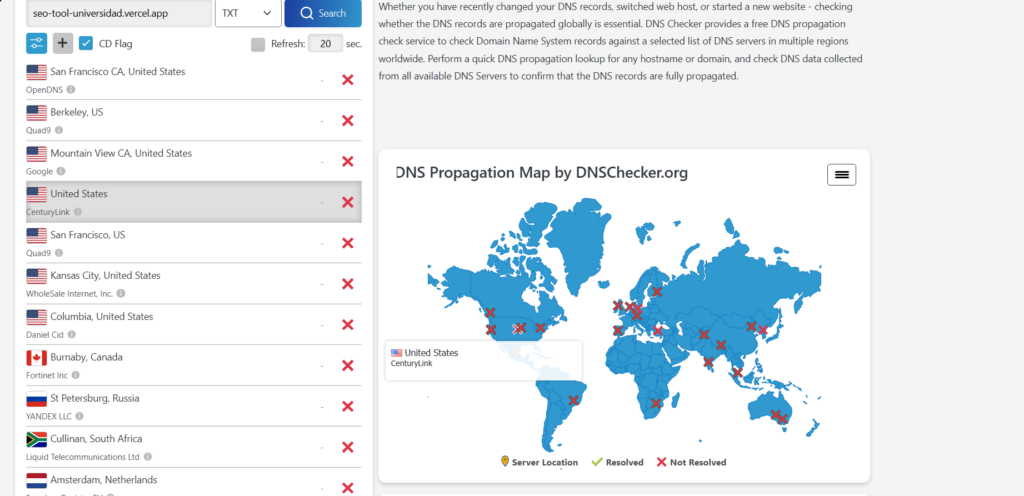
Con esto también podemos concluir que no presenta fugas de información por tercero, ya que muchas empresas usan registros TXT para verificar la propiedad de herramientas de terceros (Google Workspace, HubSpot, Facebook Pixel, etc.). Ni tampoco se exponen tokens de terceros en donde puedan llegar al punto central de Vercel.
Por ultimo revisaremos que nuestra página web presente un certificado SSL, este tipo de certificados permite el cifrado de datos entre el servidor y el cliente. Para esto utilizaremos un método mas practico, que es revisando dentro de la página web de nuestra app desplegada, en donde la propia pagina nos indica que si presenta certificado.
Nos dirigimos a la pagina donde se encuentra desplegada nuestra aplicativo:
Nos dirigimos al símbolo de candado que se encuentra al lado de la dirección URL:

Luego se despliega un menú y seleccionamos la conexión es segura:
Y de ahi seleccionamos “El certificado es valido”
Y de eso nos despliega toda la información de cifrado de seguridad de la página:
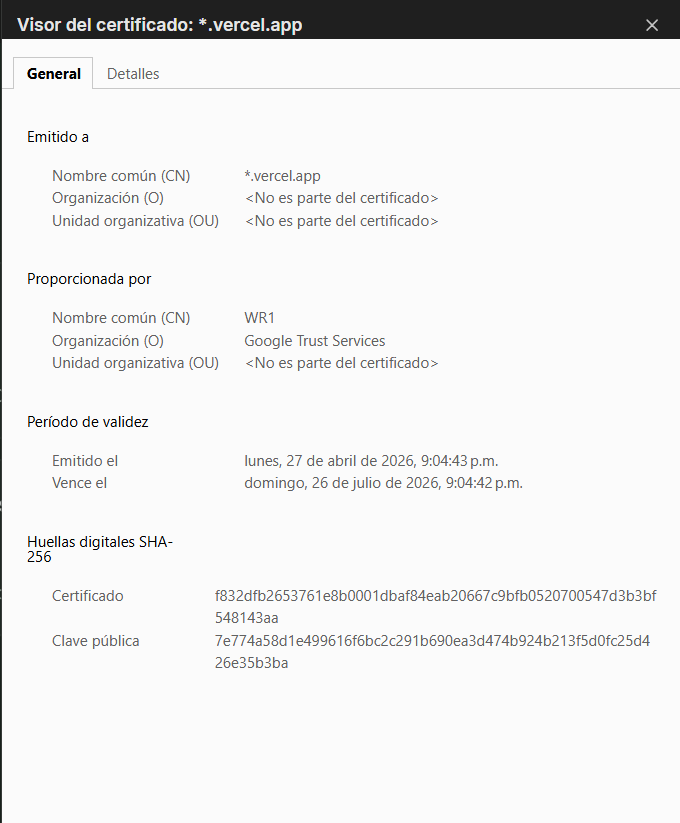
Con esto tenemos información importante sobre el certificado, como cuando se vence el certificado de cifrado, esta información es importante para un ciber-atacante para poder acceder a datos de un cliente o alterar información de este mismo, con un método MITM (Man-in-the-Middle)
Capa de seguridad: auditoría OWASP integrada en el flujo de desarrollo
Una de las desventajas conocidas del Vibe Coding es que el código generado puede omitir controles de seguridad críticos. En una plataforma que recibe URLs arbitrarias del usuario y las navega con un navegador headless, eso es un riesgo concreto: Server-Side Request Forgery (SSRF) hacia recursos internos, secrets hardcoded en componentes cliente, *verbose errors* que filtran rutas internas, XSS en contenido scrapeado que se reinyecta en el dashboard.
Para mitigar esto, el repositorio incluye una skill personalizada llamada `reviewer-owasp` que ejecuta una auditoría estática siguiendo la metodología de seis fases de identificación de vulnerabilidades (reconocimiento, escaneo y enumeración, escaneo automatizado, análisis manual, validación con PoC conceptual, informe priorizado por CVSS) propuesta por la Facultad de Ingeniería y Ciencias Básicas de la Universidad Central (Universidad Central, s.f.).
La skill cruza esa taxonomía académica con el OWASP Top 10 (OWASP Foundation, 2021) y los identificadores CWE de MITRE (MITRE Corporation, 2024), genera un reporte markdown priorizado por puntaje CVSS v3.1 (FIRST, 2019) y pregunta explícitamente al desarrollador si desea remediar los hallazgos antes de tocar una sola línea de código. Es una pieza pequeña pero clave: convierte la auditoría de seguridad en parte del flujo cotidiano y no en un evento que se hace “cuando hay tiempo”.
Conclusión
lemuSeo demuestra que el Vibe Coding es viable para construir plataformas empresariales reales, siempre que se combine con una capa de gobernanza. Para nosotros esa capa fue SDD/OpenSpec, pero la lección de fondo es más general: las IAs son excelentes generando código, mediocres definiendo qué debería hacer ese código, y francamente malas sosteniendo coherencia arquitectónica a lo largo del tiempo. Esos tres roles los tiene que poner el humano.
El equipo que construyó la plataforma no necesitó dominar React, Tailwind, TypeScript ni Go. Lo que sí necesitó fue saber qué problema estaba resolviendo, cómo se vería una solución correcta y cómo verificar que la IA estaba produciendo lo correcto. Esa es, en última instancia, la habilidad que el Vibe Coding está convirtiendo en la más valiosa.
Profundizar en el código: el repositorio está abierto
Este artículo cubre las decisiones de diseño y la metodología, pero el detalle técnico fino —cada chequeo WooRank, el contrato exacto del scraper, el código del simulador determinista de GSC, los tests de sentimiento— vive en el repositorio público:
https://github.com/bue221/seo-tool-universidad
https://seo-tool-universidad.vercel.app
Quien quiera entender cómo se construyó lemuSeo a fondo puede empezar por estos puntos de entrada:
AGENTS.MD — Arquitectura de agentes, contrato HTTP entre `dashboard-web` y `scraper-api`, decisiones clave (por qué sin Service Accounts de Google, por qué Playwright en vez de colly, por qué sentimiento heurístico en vez de LLM).
– openspec/specs/audit-contract/spec.md — Contrato de datos v0.2.0 entre frontend y scraper. Fuente de verdad de la API.
– openspec/specs/dashboard-web/spec.md — Spec actual del dashboard (v0.7.0), con todos los módulos UI y sus capacidades observables.
– openspec/changes/archive/ — La historia completa del producto en specs. Cada subcarpeta es un cambio archivado con su `proposal.md`, `design.md` y `tasks.md`. Leerlas en orden cronológico es leer cómo evolucionó lemuSeo decisión por decisión:
– `web-foundation` — i18n, theming, SEO de la propia plataforma.
– `ui-foundation` — 16 primitivos Shadcn/ui + lucide + sonner.
– `woorank-checker` — los 16 chequeos técnicos + tests en Go.
– `gsc-simulator` — el simulador determinista con PRNG sembrado por dominio.
– `competitor-compare` — el comparador multi-dominio con radar SVG.
– scraper-api/internal/audit/ — Núcleo del motor: `onpage.go`, `tracking.go`, `keywords.go`, `sentiment.go`, `woorank.go`, con sus tests respectivos.
– dashboard-web/src/lib/ — Capa de orquestación: cliente del scraper, PageSpeed Insights, integración Supabase, generador del simulador GSC.
– .claude/skills/reviewer-owasp/ — La skill de auditoría OWASP descrita en este artículo, con su checklist completo de patrones de detección.
Leer un repositorio bien gobernado por specs es, en muchos sentidos, más instructivo que leer la documentación: las specs cuentan por qué se tomó cada decisión, los commits cuentan cómo se materializó, y los tests cuentan qué se considera correcto. Todo eso es público.
Recursos técnicos del proyecto
– Repositorio público: https://github.com/bue221/seo-tool-universidad
– Specs activas: `openspec/specs/audit-contract`, `openspec/specs/dashboard-web`
– Changes archivados: `web-foundation`, `ui-foundation`, `woorank-checker`, `gsc-simulator`, `competitor-compare`
– Skill de seguridad: `.claude/skills/reviewer-owasp`
– Contrato de datos: `audit-contract` v0.2.0
Aplicación web incrustada:
Créditos:
Autores: Omar Daniel Gaitán Porras, Andrés Camilo Plaza Jiménez, Kevin Camilo Lozano Castellanos
Editor: Carlos Iván Pinzón Romero
Código: UCHE-1
Universidad: Universidad Central
Fuentes
Anysphere. (2025). *Cursor: The AI code editor* [Sitio web del producto]. https://www.cursor.com/
Collins Dictionary. (2025, noviembre). Word of the year 2025: Vibe coding. *Collins Dictionary Language Blog*. https://www.collinsdictionary.com/woty
FIRST. (2019). *Common Vulnerability Scoring System version 3.1: Specification document*. Forum of Incident Response and Security Teams. https://www.first.org/cvss/v3.1/specification-document
Karpathy, A. [@karpathy]. (2025, 2 de febrero). *There’s a new kind of coding I call “vibe coding”…* [Publicación en X]. X. https://x.com/karpathy/status/1886192184808149383
Lovable. (2025). *Lovable: Build software with words* [Sitio web del producto]. https://lovable.dev/
MITRE Corporation. (2024). *Common Weakness Enumeration (CWE) list version 4.14*. https://cwe.mitre.org/
Next.js. (2025). *Next.js 15 documentation*. Vercel. https://nextjs.org/docs
OWASP Foundation. (2021). *OWASP Top 10: 2021* [Estándar de seguridad de aplicaciones web]. https://owasp.org/Top10/
Playwright. (2025). *Playwright for Node.js: End-to-end testing and automation* [Documentación técnica]. Microsoft. https://playwright.dev/
Supabase. (2025). *Supabase documentation: Row Level Security*. https://supabase.com/docs/guides/auth/row-level-security
Tan, G. [@garrytan]. (2025, marzo). *25% of YC Winter 2025 startups have 95% AI-generated codebases* [Publicación en X]. X. https://x.com/garrytan
Universidad Central, Facultad de Ingeniería y Ciencias Básicas. (s.f.). *Identificación de vulnerabilidades: Estrategias y metodologías para la ciberseguridad proactiva* [Documento técnico]. Universidad Central de Colombia.
Y Combinator. (2025). *YC Winter 2025 batch overview*. https://www.ycombinator.com/blog
Plaza Jiménez, A. C. (2026). *seo-tool-universidad: Plataforma lemuSeo de auditoría SEO con Vibe Coding y Spec-Driven Development* [Código fuente]. GitHub. https://github.com/bue221/seo-tool-universidad
OpenSpec Contributors. (2025). *OpenSpec: Spec-driven development for AI coding agents* [Software de código abierto]. GitHub. https://github.com/Fission-AI/OpenSpec







