
IA y cine digital: construcción de personajes tridimensionales
Durante décadas, la creación de personajes digitales ha sido un proceso reservado para estudios con equipos especializados, largos tiempos de producción y flujos técnicos complejos. Modelar una figura tridimensional creíble implicaba dominar múltiples disciplinas: escultura digital, anatomía, materiales, iluminación y animación. Sin embargo, la evolución reciente de la inteligencia artificial ha comenzado a transformar este paradigma de manera profunda.
Hoy en día, es posible concebir un personaje cinematográfico y materializarlo en cuestión de minutos mediante herramientas generativas capaces de interpretar lenguaje visual y técnico. En este escenario emerge Meshy, una plataforma que propone una nueva forma de abordar el modelado tridimensional: reducir la distancia entre la idea y su representación digital. Su enfoque no consiste únicamente en automatizar tareas, sino en redefinir el modo en que se construyen activos para cine, videojuegos y entornos virtuales.
Este artículo explora la creación de personajes tridimensionales inspirados en el cine mediante el uso de inteligencia artificial, analizando el flujo completo desde la conceptualización hasta la obtención de modelos listos para producción. Más allá de presentar resultados, se busca comprender el alcance real de estas tecnologías y su impacto en el futuro del diseño digital.
¿Qué es Meshy?
Meshy es una plataforma de inteligencia artificial especializada en la generación automática de modelos tridimensionales. Su propuesta consiste en transformar ideas ya sean expresadas mediante un prompt o imágenes las cuales luego de ser procesadas estaran listos para ser utilizados en videojuegos, animación o producción audiovisual. A diferencia de herramientas centradas únicamente en imágenes, Meshy trabaja directamente sobre geometría volumétrica, lo que permite obtener modelos funcionales dentro de un pipeline real de producción.
Y es que más que una simple aplicación, Meshy representa un cambio en la forma en que se concibe el modelado 3D: el proceso creativo ya no comienza necesariamente en un software de escultura digital, sino en el lenguaje y la conceptualización visual.
¿De dónde nace Meshy?
El surgimiento de Meshy responde a la convergencia entre dos fenómenos tecnológicos: la expansión de la inteligencia artificial generativa y la creciente demanda de contenido tridimensional en la industria digital. En un entorno donde la producción de videojuegos, experiencias inmersivas y cine digital exige rapidez y eficiencia, el modelado tradicional comenzó a evidenciar limitaciones operativas.
Meshy nace como respuesta a esta necesidad, integrando modelos de aprendizaje automático capaces de interpretar formas, materiales y proporciones. Su desarrollo se enmarca en una nueva generación de herramientas que buscan automatizar etapas del pipeline creativo sin sustituir la intervención humana, sino ampliando sus posibilidades.
¿Qué busca solucionar?
El principal problema que Meshy intenta resolver es la brecha entre la idea creativa y su ejecución técnica. Tradicionalmente, transformar un concepto en un personaje tridimensional implicaba dominar múltiples disciplinas y dedicar largos periodos de trabajo.
Con la automatización de procesos como la generación de mallas, UV mapping y texturizado, Meshy reduce tiempos de producción y facilita el acceso a la creación 3D profesional. Esto permite que artistas, desarrolladores independientes y estudios pequeños puedan materializar proyectos con mayor rapidez y menor inversión de recursos.
Flujo de trabajo general en Meshy
El proceso de creación mediante esta plataforma puede comprenderse como una secuencia estructurada:
- Conceptualización y prompt: Todo inicia con la descripción del personaje o la carga de una imagen de referencia.
- Generación de la malla tridimensional: La IA construye la geometría base con topología optimizada.
- Evaluación técnica del modelo: Se revisa el wireframe para detectar errores estructurales.
- Aplicación de materiales y texturas PBR: Se generan mapas físicos que determinan la apariencia del objeto.
- Exportación e integración: El modelo puede ser utilizado en motores gráficos o software de animación.
Este flujo redefine la relación entre diseño conceptual y producción técnica.
Conceptos fundamentales del modelado 3D
Modelado tridimensional
El modelado 3D es el proceso mediante el cual se crean representaciones digitales de objetos o personajes en un espacio virtual. A través de polígonos, vértices y superficies, es posible construir estructuras que simulan volumen, peso y materialidad.
Este proceso constituye la base de la producción visual contemporánea en múltiples industrias.
Shader
Un shader es el conjunto de instrucciones que define cómo interactúa la luz con la superficie de un objeto. Determina si un material se percibe como metálico, plástico, orgánico o textil. En términos técnicos, los shaders son programas ejecutados en la GPU que calculan el color final de cada píxel en función de múltiples variables físicas.
Ray Tracing
El ray tracing es una técnica de renderizado que simula el comportamiento real de la luz. En lugar de aproximar sombras y reflejos, traza rayos virtuales que interactúan con los objetos de la escena. Este método permite obtener resultados visuales con alto grado de realismo, especialmente en superficies reflectantes o transparentes.
UV Mapping
El UV mapping consiste en desplegar la superficie de un modelo tridimensional en un plano bidimensional para aplicar texturas. Este proceso puede compararse con desdoblar una figura geométrica compleja para pintar su superficie. Un UV mapping eficiente evita distorsiones y mejora la calidad visual del material.
Topología 3D
La topología describe la organización de los polígonos que componen un modelo. No solo influye en la estética, sino también en la funcionalidad del objeto. Una topología adecuada facilita la animación, evita deformaciones incorrectas y optimiza el rendimiento en tiempo real.
Texturizado PBR
El texturizado basado en PBR (Physically Based Rendering) utiliza mapas físicos para definir la apariencia de un material. Entre ellos destacan el albedo, el normal map y el roughness. Este enfoque permite que los objetos respondan de manera coherente a diferentes condiciones de iluminación.
Subsurface Scattering
El subsurface scattering es un fenómeno óptico que simula la penetración de la luz en materiales translúcidos, como la piel humana. Este efecto aporta realismo a los modelos orgánicos al reproducir la forma en que la luz se dispersa bajo la superficie.
Wireframe Model
Un wireframe es la representación estructural de un modelo tridimensional, mostrando únicamente sus aristas y polígonos. Esta visualización permite analizar la calidad técnica de la malla antes de aplicar materiales o iluminación.
Otros conceptos fundamentales dentro del modelado 3D y su relación con Meshy
La creación de personajes tridimensionales no depende únicamente del modelado geométrico. En un pipeline profesional intervienen múltiples procesos que garantizan que el activo digital sea funcional, optimizado y listo para producción. Comprender estos conceptos permite dimensionar el impacto real de herramientas basadas en inteligencia artificial.
Retopología
La retopología es el proceso de reorganizar la estructura poligonal de un modelo para optimizar su funcionamiento. Un modelo esculpido puede tener millones de polígonos, lo que dificulta su uso en tiempo real. La retopología permite reducir esa complejidad manteniendo la forma visual.
Meshy automatiza parcialmente este proceso al generar mallas con distribución poligonal optimizada, lo que facilita su uso en motores gráficos sin requerir reconstrucción manual completa.
Rigging
El rigging consiste en la creación de un sistema de huesos digitales que permite animar un modelo tridimensional. Sin rigging, un personaje sería una figura estática. Este proceso define cómo se deformará la geometría durante movimientos o expresiones.
La generación de modelos en pose T es fundamental porque facilita la integración posterior en sistemas de rigging estándar utilizados en software como Blender o motores como Unity.
Baking de texturas
El baking es la transferencia de información visual desde un modelo de alta resolución hacia uno optimizado. Esto permite mantener detalles complejos en superficies de baja carga computacional.
Aunque Meshy genera texturas automáticamente, el baking sigue siendo relevante en producción avanzada para optimización de rendimiento.
Level of Detail (LOD)
El LOD es una técnica utilizada para mejorar el rendimiento en aplicaciones interactivas. Consiste en crear versiones simplificadas de un modelo que se utilizan cuando el objeto está lejos de la cámara.
Los modelos generados mediante IA pueden ser posteriormente adaptados a distintos niveles de detalle según los requerimientos del proyecto.
Normal Mapping
El normal mapping es una técnica que simula detalles superficiales sin necesidad de aumentar la geometría. Permite representar arrugas, poros o relieves mediante información de iluminación.
Meshy utiliza este tipo de mapas dentro de su sistema de texturizado PBR para mejorar el realismo visual sin incrementar el peso del modelo.
Ambient Occlusion
La oclusión ambiental es un efecto que simula cómo la luz se atenúa en zonas donde las superficies se encuentran próximas. Este recurso aporta profundidad visual y realismo a los materiales.
Los mapas de ambient occlusion generados automáticamente permiten mejorar la percepción volumétrica del modelo.
Escalado y unidades en el espacio 3D
En producción digital, la escala real del modelo es crucial. Un personaje debe tener dimensiones coherentes con el entorno en el que será utilizado.
Meshy genera modelos en escalas compatibles con pipelines estándar, lo que facilita su integración en escenas complejas sin necesidad de ajustes drásticos.
Exportación e integración en software y motores gráficos
Uno de los aspectos más relevantes de la generación de modelos mediante inteligencia artificial es su capacidad de integrarse en entornos de producción reales. Meshy permite exportar los modelos en formatos tridimensionales ampliamente utilizados en la industria, como:
- FBX (Filmbox): estándar para animación y videojuegos.
- OBJ: formato universal para modelado y renderizado.
- GLB / GLTF: optimizado para aplicaciones en tiempo real y web.
Gracias a esta compatibilidad, los modelos pueden ser importados directamente en:
- Unity, para desarrollo de videojuegos, simulaciones y experiencias interactivas.
- Unreal Engine, utilizado en cine digital, videojuegos AAA y visualización arquitectónica.
- Blender, para edición, animación, renderizado y ajustes técnicos.
- Maya o 3ds Max, en entornos de producción profesional.
Esta interoperabilidad convierte a Meshy en una herramienta útil no solo para generación conceptual, sino también como parte de pipelines productivos reales.
Inteligencia artificial y evolución del pipeline 3D
La automatización de procesos como la generación de mallas o el texturizado no elimina la necesidad de conocimiento técnico. Por el contrario, transforma el rol del artista digital, quien pasa de ejecutar tareas repetitivas a supervisar, ajustar y optimizar resultados generados por sistemas inteligentes.
Este cambio implica una transición desde un enfoque artesanal hacia uno híbrido, donde creatividad humana y capacidad computacional convergen para ampliar las posibilidades del diseño tridimensional.
Función de estos elementos dentro del pipeline 3D
Dentro del pipeline de producción, cada uno de estos conceptos cumple una función específica. El modelado define la forma, la topología garantiza la funcionalidad, el UV mapping prepara la superficie, el texturizado determina la apariencia y los shaders permiten la interacción con la luz. Finalmente, el renderizado traduce todos estos elementos en una imagen visible.
Comprender esta secuencia es esencial para evaluar el impacto de herramientas como Meshy, ya que la automatización de estas etapas redefine el equilibrio entre creatividad y técnica en la producción digital.
Construcción de personajes mediante prompts en Meshy
Una vez comprendidos los fundamentos técnicos del modelado tridimensional y el funcionamiento del pipeline digital, el siguiente paso consiste en trasladar estos conceptos a la práctica mediante el uso de la plataforma Meshy. La generación de personajes en este entorno no se limita a escribir una descripción; implica un proceso iterativo de exploración visual y refinamiento conceptual.
Acceso a la generación de modelos
El proceso inicia desde la página principal de Meshy, donde se encuentra la opción Image to 3D. Esta modalidad permite generar modelos tridimensionales a partir de imágenes de referencia o descripciones técnicas detalladas. A diferencia de otros sistemas generativos, esta herramienta no produce únicamente representaciones visuales, sino geometría funcional exportable.
Dentro de esta sección se dispone de un campo principal destinado a la inserción de imágenes o prompts. Sobre este campo se encuentra la opción denominada Helper, que constituye una de las funciones más relevantes del flujo de trabajo.
Uso de la herramienta Helper
La opción Helper permite ingresar descripciones extensas del personaje sin consumir créditos. Este espacio funciona como un entorno de experimentación conceptual donde el usuario puede ajustar progresivamente el nivel de detalle del prompt. A medida que se introducen cambios, la plataforma genera diferentes interpretaciones visuales del modelo.
Esta fase resulta fundamental, ya que permite evaluar múltiples variantes antes de proceder a la generación definitiva. De esta manera, el usuario puede analizar proporciones, materiales, silueta y coherencia estética sin incurrir en costos adicionales.
El Helper actúa, en términos prácticos, como un sistema de previsualización inteligente que traduce lenguaje descriptivo en aproximaciones visuales. Este enfoque favorece un proceso creativo iterativo, donde la precisión del prompt se convierte en el principal factor determinante del resultado final.
Generación del modelo tridimensional
Una vez seleccionado el diseño más cercano al objetivo visual, se procede a utilizar la opción de generación definitiva. Este proceso implica el consumo de créditos dentro de la plataforma, siendo necesario invertir un total aproximado de 20 créditos por modelo generado.
Durante esta etapa, la inteligencia artificial construye la malla tridimensional completa, integrando geometría, topología y materiales base. El resultado obtenido corresponde a un modelo tridimensional funcional que puede ser posteriormente revisado, ajustado o exportado.
Importancia del prompt en la fidelidad del modelo
El uso de prompts detallados permite reducir errores comunes en la generación automática, como deformaciones anatómicas, inconsistencias en materiales o pérdida de identidad visual. En el contexto de personajes cinematográficos, la precisión descriptiva adquiere mayor relevancia debido a la complejidad de los rasgos, vestimenta y accesorios.
Por esta razón, el proceso de construcción del prompt no debe entenderse como una simple descripción, sino como una especificación técnica del modelo tridimensional. Cada elemento textual contribuye a definir la estructura geométrica, la respuesta de los materiales y la coherencia visual del personaje.
Del concepto al modelo funcional
El flujo de trabajo descrito demuestra cómo la inteligencia artificial redefine la producción de personajes digitales. Lo que anteriormente requería múltiples etapas manuales puede ahora concentrarse en un proceso guiado por iteración conceptual y supervisión técnica.
En este sentido, Meshy no sustituye el conocimiento del modelador, sino que introduce una nueva dinámica de creación donde la precisión conceptual se traduce directamente en resultados tridimensionales.
Los personajes: del prompt al resultado
Con el flujo de trabajo establecido y el uso del Helper como herramienta de exploración conceptual, se procedió a la generación de personajes cinematográficos icónicos mediante prompts estructurados. Cada caso representó un desafío técnico distinto relacionado con materiales, proporciones, anatomía o complejidad geométrica.
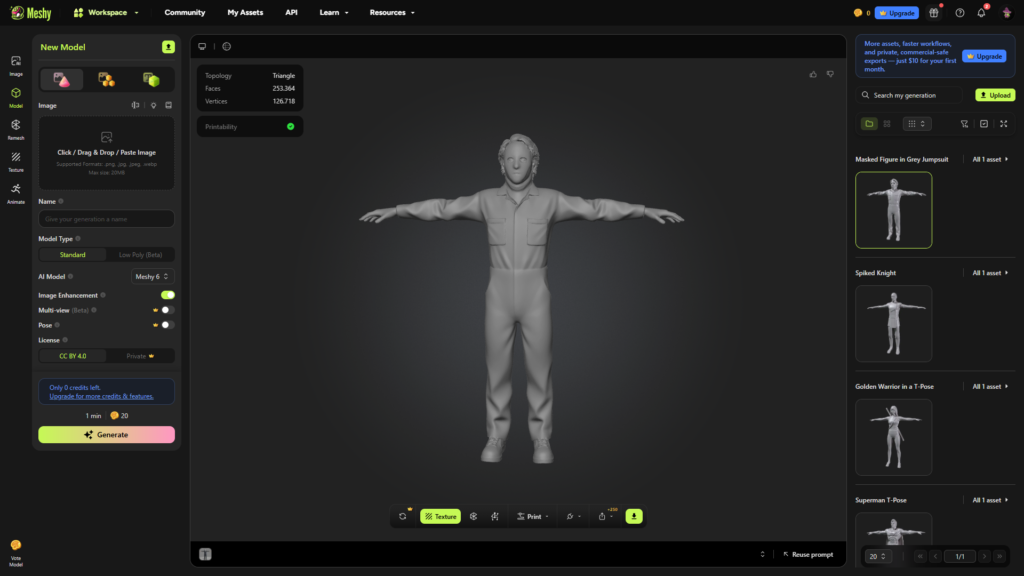
MICHAEL MYERS
Análisis técnico
El principal desafío fue lograr una representación convincente de una figura minimalista pero altamente icónica. A diferencia de otros personajes con complejidad material elevada, el reto consistió en mantener la neutralidad expresiva de la máscara y la simplicidad del vestuario sin perder realismo físico. La correcta lectura de proporciones humanas, caída textil y comportamiento de materiales resultó fundamental para preservar la presencia visual característica del personaje.
Prompt utilizado
Personaje 3D humanoide completo inspirado en estética cinematográfica realista en pose T estricta, cuerpo entero visible, brazos extendidos exactamente a 90 grados, manos abiertas con dedos separados y visibles, postura neutra simétrica, modelo centrado.
Rostro y cabeza: máscara blanca lisa con textura mate ligeramente envejecida y variaciones tonales sutiles, orificios oculares simétricos con ojos humanos visibles en el interior, cabello corto oscuro con ligera ondulación y distribución natural.
Piel: textura humana visible en cuello y manos con subsurface scattering moderado, microdetalle de poros y variación tonal natural.
Cuerpo: anatomía robusta con proporciones humanas realistas, hombros anchos, estructura corporal sólida y manos grandes correctamente formadas.
Vestimenta: mono de trabajo industrial gris azulado con arrugas naturales, costuras visibles, desgaste leve en zonas de tensión, botas de trabajo oscuras con textura envejecida.
Accesorio: objeto utilitario metálico de forma simple con acabado industrial y desgaste físico controlado.
Materiales: set PBR completo con albedo realista, normal map en textiles, roughness variable, metallic sutil en elementos metálicos.
Modelado: topología limpia optimizada para rigging humanoide y uso game-ready.
Iluminación: esquema de tres puntos con fondo gris neutro.
Render: vista frontal ortográfica en resolución 4K.
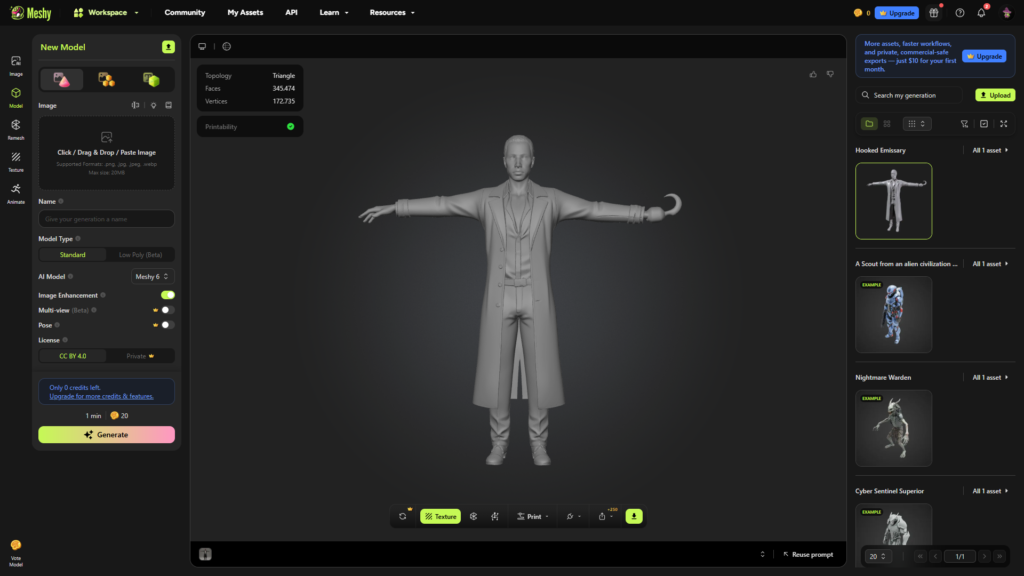
CANDYMAN
Análisis técnico
Este personaje presentó un reto particular en la integración de elementos orgánicos y simbólicos, especialmente en la representación de superficies cutáneas perforadas y la inclusión opcional de enjambres de abejas. La correcta combinación entre materiales orgánicos, textiles oscuros y metal reflectante fue determinante para la fidelidad del resultado.
Prompt utilizado
Personaje humanoide completo inspirado en estética cinematográfica sobrenatural en pose T estricta, cuerpo entero visible, brazos extendidos exactamente a 90 grados, manos abiertas con dedos separados, postura neutra simétrica, modelo centrado.
Rostro y cabeza: rostro humano adulto con múltiples perforaciones pequeñas distribuidas irregularmente, expresión neutra solemne, ojos realistas con reflejos húmedos, cabello oscuro corto.
Opción alternativa (con abejas): pequeñas abejas visibles sobre el rostro y el torso, distribuidas de forma orgánica sin cubrir completamente las facciones.
Piel: textura humana realista con microdetalle visible y subsurface scattering moderado.
Cuerpo: figura alta y delgada con proporciones naturales.
Vestimenta: abrigo largo oscuro de estilo clásico, camisa interior clara parcialmente abierta, pantalón oscuro ajustado.
Accesorio: una mano sustituida por gancho metálico pulido con reflectividad física realista.
Materiales: PBR completo con roughness variable en piel, reflectividad controlada en metal y textura textil detallada.
Modelado: topología limpia optimizada para animación.
Iluminación: neutra cinematográfica con contraste medio.
Render: frontal ultra detallado en 4K.
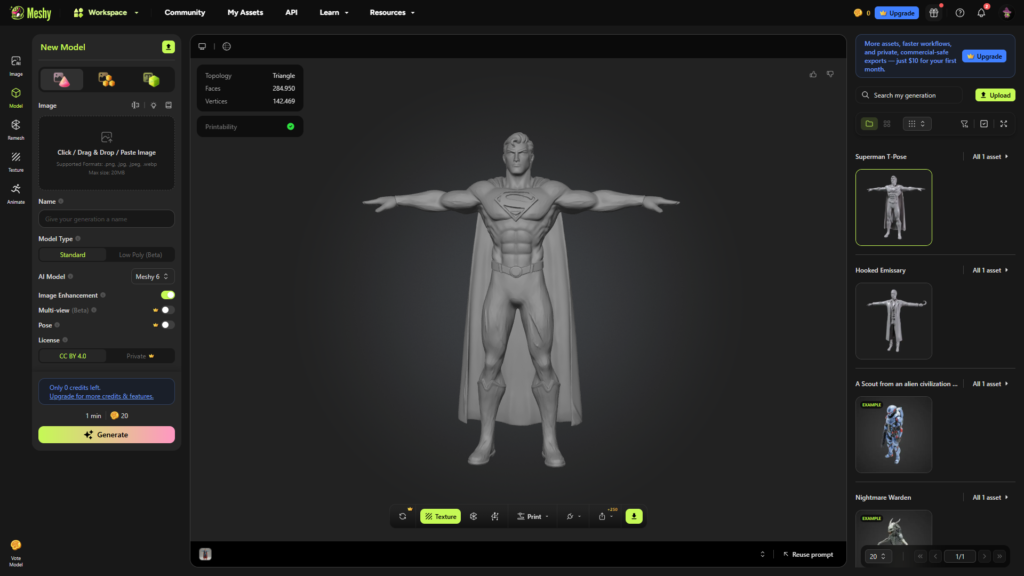
SUPERMAN (VERSIÓN CLÁSICA)
Análisis técnico
El desafío principal fue mantener proporciones heroicas clásicas sin caer en estilización contemporánea. La simulación del comportamiento de materiales elásticos y la correcta lectura del símbolo torácico fueron factores clave.
Prompt utilizado
Personaje superhéroe humano completo en pose T estricta, cuerpo entero visible, brazos extendidos a 90 grados, dedos separados, postura simétrica.
Rostro: mandíbula definida, ojos azules realistas, cabello negro con rizo frontal característico.
Piel: realista con subsurface scattering.
Cuerpo: físico atlético musculoso clásico.
Vestimenta: traje azul ajustado tipo spandex, capa roja larga fluida, botas rojas, cinturón amarillo, símbolo torácico rojo y amarillo.
Materiales: texturizado PBR con normal map fino y roughness controlado.
Modelado: optimizado para animación corporal.
Iluminación: neutra cinematográfica.
Render: frontal 4K.
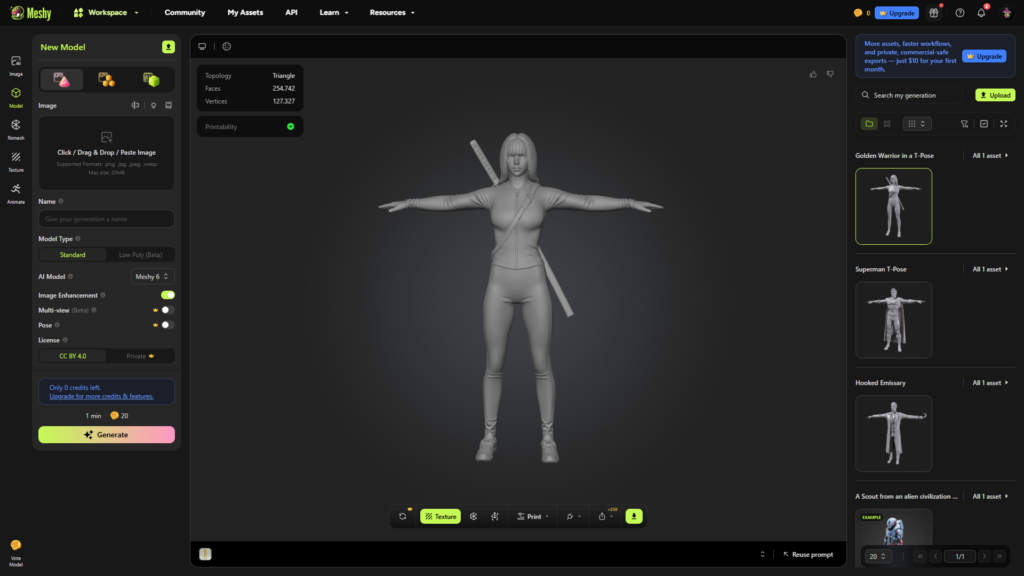
KILL BILL — THE BRIDE
Análisis técnico
El reto consistió en reproducir la estética minimalista y el comportamiento físico del traje sintético deportivo manteniendo la silueta atlética cinematográfica del personaje.
Prompt utilizado
Personaje femenino humano completo en pose T estricta.
Rostro: rasgos realistas, cabello rubio liso con flequillo.
Piel: realista con subsurface scattering ligero.
Cuerpo: atlético estilizado.
Vestimenta: mono deportivo amarillo con líneas negras laterales, zapatillas deportivas amarillas.
Accesorio: katana japonesa sostenida en reposo.
Materiales: PBR sintético deportivo con reflectividad controlada.
Modelado: optimizado para animación de combate.
Iluminación: suave de estudio.
Render: frontal 4K.
PINHEAD
Análisis técnico
El mayor desafío técnico fue la correcta distribución geométrica de elementos metálicos craneales y la integración de materiales orgánicos y cuero estructurado sin deformaciones.
Prompt utilizado
Humanoide completo en pose T estricta.
Rostro: cabeza extremadamente pálida con patrón geométrico preciso formado por clavos metálicos finos distribuidos uniformemente.
Piel: textura orgánica con microdetalle y subsurface scattering bajo.
Cuerpo: figura delgada con postura rígida ceremonial.
Vestimenta: túnica negra estructurada con paneles geométricos y detalles de cuero.
Materiales: set PBR completo con cuero mate, metal reflectante y tejido orgánico.
Modelado: topología facial precisa optimizada para animación.
Iluminación: fría dramática.
Render: ultra detallado frontal.
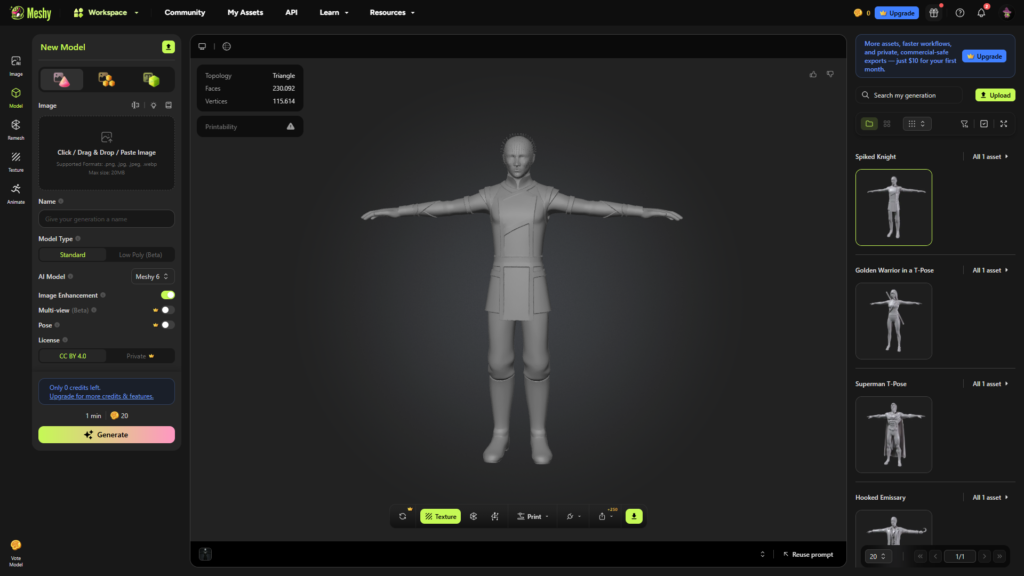
Proceso práctico de creación mediante referencia visual
Una de las características más relevantes de Meshy es la posibilidad de generar modelos tridimensionales a partir de imágenes. Este enfoque permite trasladar referencias cinematográficas o conceptuales directamente al entorno de modelado asistido por inteligencia artificial, reduciendo la distancia entre la idea visual y el resultado tridimensional.
El proceso de generación mediante imágenes se desarrolla en una secuencia clara que combina interpretación automática y supervisión del usuario.
Paso 1 — Acceso a la herramienta de generación
Desde la página principal de la plataforma, el usuario debe seleccionar la opción Image to 3D, la cual permite iniciar el proceso de construcción del modelo basado en referencias visuales.
Esta modalidad se diferencia de la generación por texto en que la inteligencia artificial recibe información directa sobre proporciones, silueta y materiales a partir de la imagen cargada.
Paso 2 — Selección del modo de creación
Una vez dentro del entorno de generación, se accede al apartado Model, donde se encuentra la opción destinada a la carga de imágenes. En esta sección es posible seleccionar archivos visuales que servirán como base para la interpretación tridimensional.
El sistema permite trabajar con una o varias referencias, lo cual facilita la definición estética del personaje desde diferentes perspectivas.
Paso 3 — Carga de imágenes de referencia
El siguiente paso consiste en cargar las imágenes previamente seleccionadas. Estas pueden corresponder a capturas cinematográficas, ilustraciones conceptuales o referencias visuales específicas del personaje a modelar.
Tras la carga, la inteligencia artificial analiza la composición visual, identificando:
- estructura general del cuerpo
- distribución de materiales
- proporciones anatómicas
- elementos distintivos del diseño
Este proceso se realiza de forma automática y constituye la base sobre la cual se construirá la geometría tridimensional.
Paso 4 — Interpretación de la inteligencia artificial
Es importante señalar que la interpretación realizada por la IA no implica una reproducción exacta de la imagen original. Dependiendo de la complejidad del diseño o de la calidad de la referencia, el modelo resultante puede presentar variaciones sutiles en proporciones, detalles o materiales.
En muchos casos, estos cambios corresponden a decisiones algorítmicas orientadas a optimizar la funcionalidad del modelo dentro de un entorno tridimensional. Por esta razón, el proceso de generación debe entenderse como una colaboración entre la intención del usuario y la interpretación del sistema.
Paso 5 — Evaluación y refinamiento del resultado
Una vez generado el modelo, el usuario puede evaluar la fidelidad visual y técnica del resultado. En caso de que existan discrepancias significativas, es posible ajustar las imágenes de referencia o complementar el proceso mediante prompts más detallados.
Este flujo iterativo permite mejorar progresivamente la precisión del modelo sin comprometer la eficiencia del pipeline.
Importancia del uso de referencias visuales
El uso de imágenes no solo mejora la fidelidad estética del personaje, sino que también contribuye a reducir errores comunes en la generación automática, como deformaciones anatómicas o incoherencias en materiales. Además, facilita la construcción de modelos que respetan la identidad visual de personajes cinematográficos complejos.
En este sentido, la generación mediante referencia visual se posiciona como una herramienta clave dentro de los procesos contemporáneos de creación tridimensional asistida por inteligencia artificial.
Comparación de resultados frente a las imágenes de referencia
Una vez completado el proceso de generación de los personajes tridimensionales, resulta fundamental evaluar el grado de fidelidad visual alcanzado por la inteligencia artificial en relación con las imágenes utilizadas como referencia. Esta comparación permite determinar la eficacia del sistema en la interpretación de proporciones, materiales y características distintivas de cada diseño.
Para este análisis, se consideraron los siguientes aspectos:
- similitud en la silueta general del personaje
- precisión en rasgos faciales y expresiones
- coherencia en vestimenta y accesorios
- comportamiento de materiales y texturas
- correspondencia entre proporciones reales y modelo generado
Cada personaje presentó un nivel distinto de fidelidad, evidenciando tanto el potencial de la herramienta como sus limitaciones actuales. En algunos casos, la IA logró una reproducción altamente cercana a la referencia, mientras que en otros se observaron variaciones relacionadas con la interpretación automática de elementos complejos.
(En esta sección se integrarán posteriormente las imágenes comparativas correspondientes a cada personaje).
Comparación de resultados: interpretación de la IA en Michael Myers
El análisis comparativo permite observar cómo la inteligencia artificial prioriza la información dependiendo del método de generación. En este caso, la diferencia entre el modelo creado mediante Helper (prompt textual) y el modelo generado a partir de una imagen evidencia variaciones en fidelidad visual, interpretación material y construcción narrativa del personaje.
Imagen 1 — Referencia cinematográfica

La imagen original presenta la construcción completa del personaje desde un enfoque narrativo. La máscara blanca funciona como un recurso simbólico que elimina la expresión humana, generando una sensación de vacío emocional característica del personaje.
El mono de trabajo transmite uso prolongado, desgaste y contexto ambiental. Estos elementos no solo aportan realismo visual, sino que también construyen la identidad psicológica del personaje dentro de la escena.
Asimismo, la postura corporal relajada pero rígida contribuye a la tensión dramática. No se trata únicamente de una pose física, sino de una manifestación de su presencia narrativa.
Imagen 2 — Modelo generado mediante Helper

Cuando la generación se basa en prompt textual, la IA interpreta correctamente los atributos conceptuales principales del personaje. La máscara mantiene su forma icónica y la anatomía presenta proporciones coherentes, lo que demuestra una lectura eficiente de instrucciones explícitas.
Sin embargo, el vestuario se representa con superficies limpias y simplificadas. La ausencia de desgaste visible indica que la IA prioriza la claridad estructural sobre la carga narrativa del diseño. Esto genera un modelo técnicamente funcional, adecuado para rigging o prototipado, pero con menor fidelidad cinematográfica.
La pose en T, aunque útil dentro del pipeline 3D, elimina la tensión psicológica del personaje. Este comportamiento confirma que la IA optimiza para producción técnica más que para interpretación dramática.
Imagen 3 — Modelo generado a partir de imagen de referencia
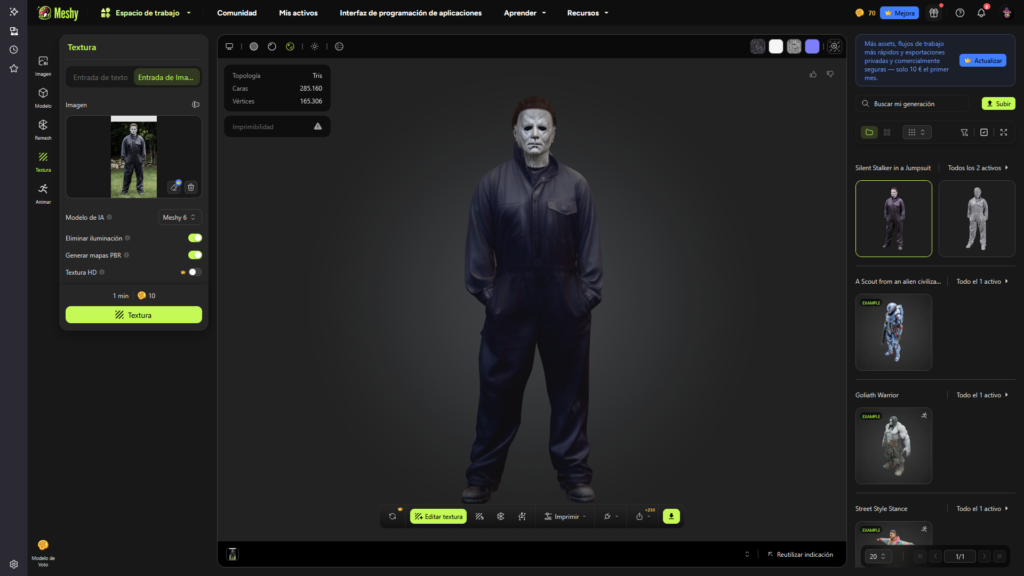
Cuando la generación parte de una imagen, la IA prioriza la lectura visual directa. En este caso, el mono de trabajo presenta una mayor aproximación al diseño cinematográfico en términos de volumen y proporción. Esto evidencia que la referencia visual aporta información espacial que el texto no siempre transmite con precisión.
No obstante, la máscara pierde parte de su identidad material. Aunque conserva la forma general, la simplificación en textura y microdetalles reduce el impacto expresivo del personaje. Esto indica limitaciones actuales en la reconstrucción de superficies con fuerte carga simbólica.
La postura también se acerca más al carácter original, pero aún muestra suavización en pliegues textiles y desgaste físico, lo que reduce la sensación de realismo contextual.
Lectura técnica del comportamiento de la IA
Este análisis permite identificar tres patrones clave en el comportamiento del sistema:
- La IA basada en texto responde mejor a atributos conceptuales explícitos.
- La IA basada en imagen mejora la interpretación volumétrica y material.
- La fidelidad narrativa sigue dependiendo del criterio artístico humano.
En consecuencia, Meshy se posiciona como una herramienta altamente eficiente para la construcción estructural y el prototipado dentro del pipeline 3D, pero no sustituye la interpretación creativa necesaria para lograr una representación cinematográfica completamente fiel.vención humana para alcanzar una representación cinematográfica plenamente expresiva.
Comparación de resultados: interpretación de la IA en Candyman
El análisis comparativo entre los modelos generados permite identificar cómo la inteligencia artificial prioriza la información según la fuente utilizada (prompt o imagen).
Imagen 1 — Modelo generado mediante Helper

En este caso, el sistema interpreta correctamente elementos descritos explícitamente en el prompt. Un ejemplo claro es el gancho, cuya presencia se mantiene debido a que forma parte de la estructura semántica del texto. Esto evidencia que la IA responde con mayor precisión cuando los atributos son definidos de forma directa.
Sin embargo, el vestuario no coincide fielmente con el del personaje cinematográfico. La razón principal es que el prompt describe características generales del abrigo, pero no transmite la complejidad material ni la construcción narrativa del diseño original. Como resultado, el modelo presenta una versión funcional del traje, adecuada para pipeline técnico, pero no para fidelidad cinematográfica.
Otro aspecto relevante es la presencia de las abejas. Estas aparecen como elementos superficiales o decorativos, lo que sugiere que la IA las interpreta como detalles simbólicos, no como componentes orgánicos integrados al personaje.
Imagen 2 — Modelo generado mediante imagen de referencia
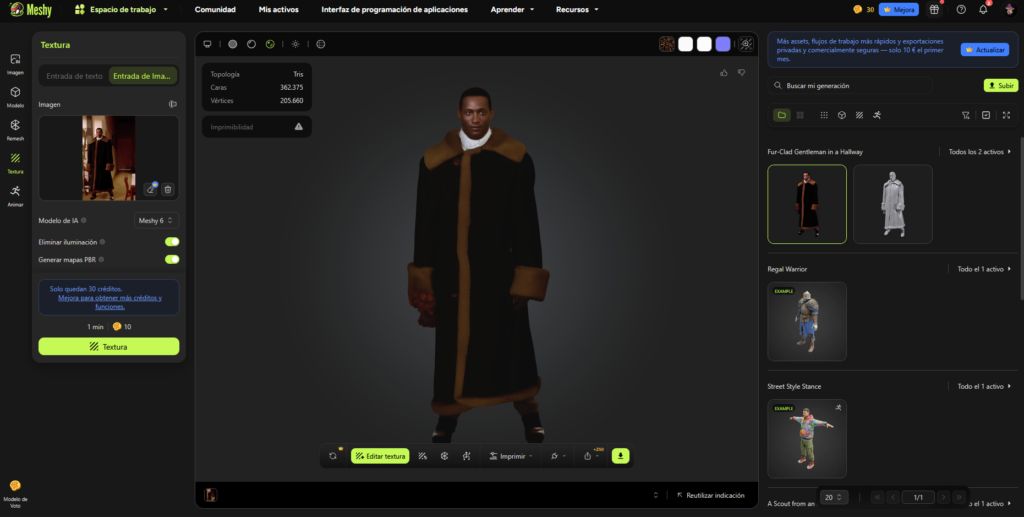
Cuando la generación se basa en una imagen, el sistema prioriza la lectura visual directa sobre la interpretación conceptual. En este caso, el gancho no se representa con claridad, ya que su forma no resulta completamente evidente en la referencia utilizada. Esto demuestra que la IA depende de la legibilidad visual de los elementos, incluso si estos son icónicos dentro de la narrativa del personaje.
Por otro lado, el vestuario se aproxima más al diseño cinematográfico. La IA logra identificar volúmenes, proporciones y materiales generales, aunque todavía simplifica la complejidad textil. Esta mejora confirma que la referencia visual aporta información espacial y material que el prompt textual no siempre logra transmitir.
No obstante, el rostro pierde parte de la identidad del personaje, evidenciando que la reconstrucción facial automática aún presenta limitaciones en precisión expresiva.
Imagen 3 — Referencia cinematográfica

La imagen original concentra la intención narrativa completa del personaje. En ella, el gancho no es solo un objeto, sino un símbolo integrado a la actuación y la puesta en escena. Asimismo, el vestuario no cumple únicamente una función estética, sino que construye la presencia dramática del personaje.
Esto permite comprender que la IA puede reproducir formas y estructuras, pero la dimensión simbólica del diseño aún depende de la interpretación artística humana.
Lectura técnica del comportamiento de la IA
Este experimento evidencia tres patrones clave:
- La IA basada en texto responde mejor a atributos explícitos.
- La IA basada en imagen responde mejor a volúmenes y materiales visibles.
- La fidelidad narrativa sigue dependiendo del criterio humano.
En consecuencia, Meshy funciona de forma más eficiente como herramienta de prototipado estructural que como sistema de reconstrucción cinematográfica exacta.
Comparación de resultados: interpretación de la IA en Superman
En este experimento se evaluó el comportamiento de la inteligencia artificial al generar el personaje de Superman bajo tres condiciones distintas: referencia cinematográfica, generación mediante Helper (prompt) y generación mediante imagen.
Imagen 1 — Referencia original

La imagen cinematográfica establece el estándar visual del personaje. En ella se observa una postura corporal expresiva, con brazos cruzados, iluminación ambiental real y un traje con comportamiento textil natural. Elementos como la capa, el símbolo en el pecho y la musculatura no solo cumplen una función estética, sino narrativa. La anatomía responde al cuerpo real del actor, lo que aporta credibilidad física y presencia dramática.
Imagen 2 — Modelo generado mediante Helper

Cuando el personaje se genera a partir de un prompt estructurado, la IA prioriza la claridad anatómica y la funcionalidad técnica del modelo. En este caso, se observa:
- La pose cambia a T-pose, ya que el sistema interpreta que el modelo debe estar preparado para animación.
- La musculatura se exagera, generando un cuerpo idealizado más cercano al cómic que al actor original.
- El traje mantiene los colores y símbolos principales, pero pierde comportamiento textil realista.
- La capa se simplifica geométricamente para favorecer la topología y el rendimiento en tiempo real.
Esto demuestra que la IA optimiza el modelo para pipeline técnico antes que para fidelidad cinematográfica.
Imagen 3 — Modelo generado a partir de imagen
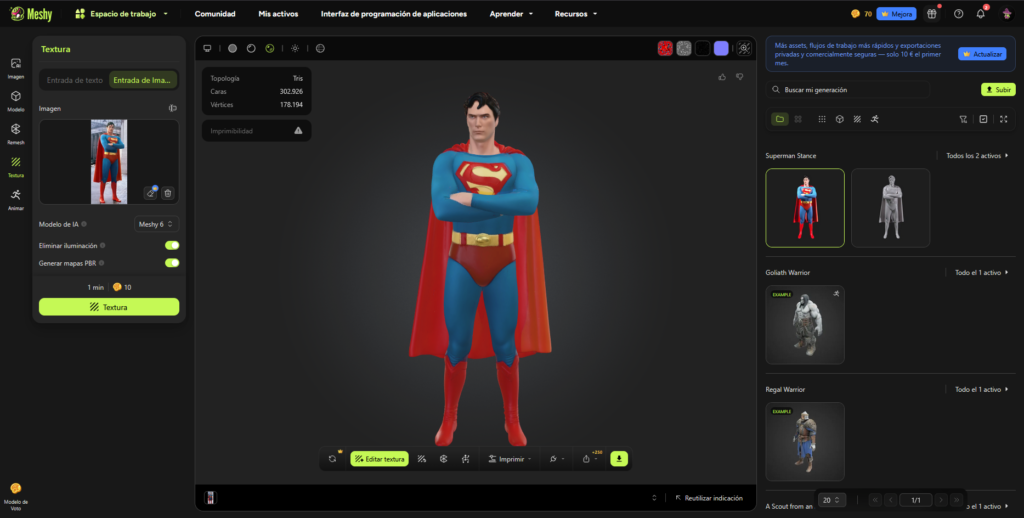
Cuando se utiliza la imagen como base, la IA intenta reconstruir la apariencia general del personaje. Sin embargo, se observan diferencias clave:
- La pose original (brazos cruzados) se mantiene parcialmente, pero el modelo presenta rigidez estructural.
- La musculatura es menos exagerada que en el Helper, pero sigue sin corresponder exactamente al actor.
- El traje presenta mayor coherencia visual que en el modelo textual, aunque aún carece de complejidad material.
- La iluminación original de la escena no se replica, ya que el sistema prioriza neutralidad de render.
Esto indica que la generación basada en imagen mejora la fidelidad visual general, pero no garantiza precisión anatómica ni narrativa.
Lectura técnica del comportamiento de la IA
El análisis del personaje permite identificar un patrón consistente en Meshy:
- El prompt textual favorece modelos técnicamente correctos para animación.
- La referencia visual favorece similitud estética general.
- La referencia cinematográfica sigue siendo superior en expresión y realismo.
En consecuencia, la IA funciona mejor como herramienta de prototipado estructural que como sistema de reconstrucción cinematográfica exacta.
Comparación de resultados: interpretación de la IA en Kill Bill
Este caso permite observar con claridad cómo la inteligencia artificial interpreta elementos icónicos cuando la generación se realiza mediante texto o mediante referencia visual directa.
Imagen 1 — Referencia cinematográfica

La imagen original presenta una construcción visual muy específica del personaje. El traje amarillo no solo define la identidad estética, sino que su materialidad, costuras y desgaste responden a una lógica narrativa. La postura corporal transmite actitud y presencia, mientras que la katana se integra como extensión natural del personaje.
Además, el comportamiento del tejido, la iluminación real y la expresión facial contribuyen a una lectura cinematográfica completa.
Imagen 2 — Modelo generado mediante Helper

En la generación basada en prompt, la IA logra identificar correctamente los elementos principales del personaje:
- El traje amarillo se mantiene como rasgo dominante.
- La katana aparece como objeto funcional dentro de la estructura del modelo.
- La pose cambia a T-pose, evidenciando que el sistema prioriza preparación para animación.
Sin embargo, se observan simplificaciones relevantes:
- El traje pierde complejidad textil y se interpreta como una superficie uniforme.
- Los detalles gráficos del vestuario no se reproducen con fidelidad.
- La expresión facial se neutraliza para favorecer simetría anatómica.
Esto confirma que el modelo textual optimiza la funcionalidad técnica antes que la fidelidad cinematográfica.
Imagen 3 — Modelo generado a partir de imagen
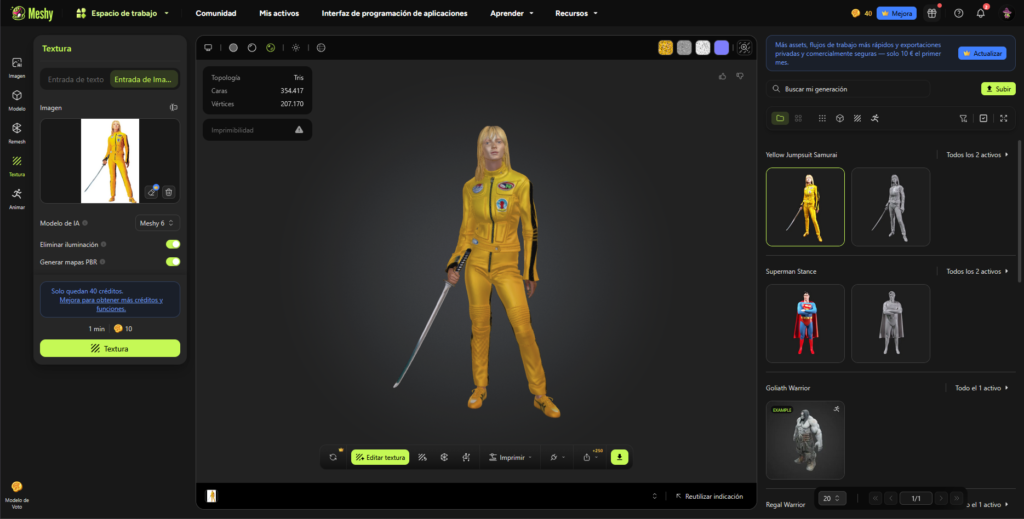
Cuando se utiliza la imagen como base, la IA mejora la coherencia visual del personaje:
- La postura corporal se aproxima más a la referencia original.
- El vestuario presenta mayor lectura volumétrica y material.
- La katana se integra de forma más natural al conjunto.
No obstante, aún se detectan limitaciones:
- Los detalles gráficos del traje siguen simplificados.
- La expresión facial pierde identidad respecto al personaje original.
- La iluminación cinematográfica no se replica, ya que el sistema genera un entorno neutral.
Lectura técnica del comportamiento de la IA
El caso de Kill Bill refuerza el patrón observado en personajes anteriores:
- El prompt textual asegura la presencia de elementos icónicos.
- La referencia visual mejora la coherencia estética general.
- La narrativa visual cinematográfica no se transfiere completamente al modelo generado.
Esto evidencia que Meshy funciona principalmente como herramienta de prototipado estructural y conceptual, siendo necesario un proceso posterior de refinamiento artístico para alcanzar fidelidad cinematográfica.
Comparación de resultados: interpretación de la IA en Pinhead
El personaje de Pinhead representa un caso especialmente interesante dentro del experimento debido a la complejidad geométrica y simbólica de su diseño. La generación mediante IA evidencia cómo el sistema prioriza distintos elementos según el tipo de entrada utilizada.
Imagen 1 — Referencia cinematográfica

La imagen original presenta una construcción visual altamente compleja. El rostro, compuesto por una retícula precisa de clavos metálicos, no solo define la identidad del personaje, sino que establece una geometría extremadamente específica. El vestuario, con múltiples capas, texturas y elementos biomecánicos, contribuye a una lectura visual rica en detalle.
Asimismo, la postura corporal y la expresión facial transmiten una presencia narrativa que va más allá de la simple representación anatómica.
Imagen 2 — Modelo generado mediante Helper

Cuando el personaje se genera mediante prompt, la IA logra identificar correctamente los elementos icónicos principales:
- La estructura general del rostro con clavos se mantiene como rasgo dominante.
- El vestuario oscuro se interpreta como un conjunto funcional para animación.
- La pose se transforma en T-pose, priorizando la preparación técnica del modelo.
Sin embargo, se evidencian simplificaciones importantes:
- La disposición de los clavos pierde precisión geométrica respecto al diseño original.
- El vestuario se reduce a formas más limpias, eliminando complejidad biomecánica.
- Los materiales presentan menor contraste físico entre piel, metal y tela.
Esto demuestra que la IA optimiza la claridad estructural del modelo por encima de la fidelidad cinematográfica.
Imagen 3 — Modelo generado a partir de imagen
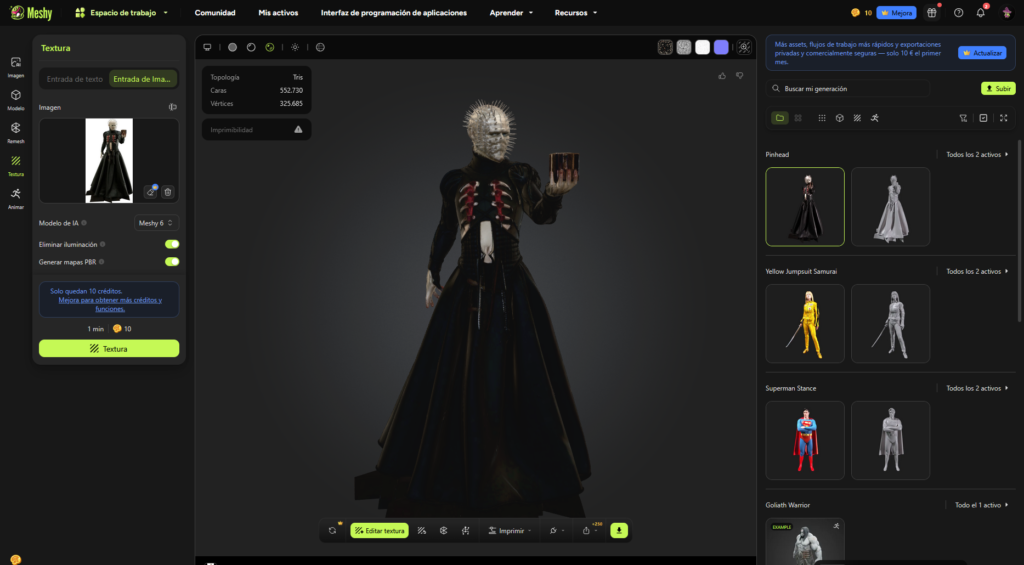
Al utilizar la imagen como referencia, la IA mejora la coherencia visual general del personaje:
- La lectura del vestuario resulta más cercana al diseño cinematográfico.
- El rostro mantiene una organización más reconocible de los clavos.
- La silueta general se aproxima mejor a la presencia original del personaje.
No obstante, aún se presentan limitaciones:
- La precisión en la retícula facial no alcanza la exactitud del diseño cinematográfico.
- Los materiales siguen simplificados en su comportamiento físico.
- La carga expresiva del personaje se reduce debido a la neutralidad del modelo generado.
Lectura técnica del comportamiento de la IA
El caso de Pinhead confirma patrones observados previamente:
- La generación por texto garantiza la presencia de elementos icónicos estructurales.
- La generación por imagen mejora la similitud estética global.
- La complejidad simbólica y material del cine no se transfiere completamente al modelo 3D automático.
Esto refuerza la idea de que Meshy funciona de forma óptima como herramienta de prototipado tridimensional y base de producción, requiriendo intervención artística posterior para alcanzar niveles cinematográficos de fidelidad.
Errores encontrados durante la generación
A pesar de los avances significativos en la generación automática de modelos tridimensionales, el proceso evidenció ciertas inconsistencias técnicas que reflejan el estado actual de estas tecnologías.
Uno de los errores más recurrentes estuvo relacionado con la estructura de las manos y los dedos. En algunos modelos, la inteligencia artificial presentó dificultades para mantener proporciones anatómicas correctas o para separar adecuadamente los dedos en la pose T. Este tipo de fallos suele requerir iteraciones adicionales o ajustes manuales posteriores.
Asimismo, se observaron inconsistencias faciales en ciertos casos, particularmente en personajes con rasgos complejos o parcialmente cubiertos. La interpretación de ojos, simetría facial o detalles finos puede variar dependiendo del nivel de especificidad del prompt o de la calidad de la imagen de referencia.
Otro aspecto relevante fue la variación en materiales. En ocasiones, superficies que debían presentar comportamientos físicos específicos —como cuero, tela o metal— mostraron respuestas visuales menos precisas, lo que evidencia la necesidad de refinamiento en la generación automática de texturas.
Finalmente, algunos modelos presentaron ligeras desviaciones en proporciones corporales, especialmente en personajes estilizados o con siluetas no convencionales. Estos resultados sugieren que la inteligencia artificial tiende a priorizar coherencia estructural general sobre exactitud absoluta en diseños complejos.
Ventajas del uso de Meshy en la creación de personajes
El uso de inteligencia artificial en la generación de modelos tridimensionales aporta múltiples beneficios dentro del pipeline de producción digital.
En primer lugar, destaca la reducción significativa del tiempo de desarrollo. La capacidad de pasar de una idea conceptual a un modelo funcional en minutos transforma la dinámica de trabajo en proyectos creativos.
Asimismo, la automatización de procesos técnicos como la generación de mallas, UV mapping y texturizado permite a los usuarios concentrarse en aspectos creativos y conceptuales, optimizando la eficiencia del flujo de trabajo.
Otro factor relevante es la accesibilidad. Herramientas como Meshy democratizan el acceso al modelado tridimensional, permitiendo que usuarios sin experiencia avanzada en escultura digital puedan obtener resultados de calidad profesional.
Finalmente, la compatibilidad con motores gráficos y software de producción facilita la integración inmediata de los modelos en proyectos reales, reduciendo fricciones entre etapas del pipeline.
Desventajas y limitaciones actuales
A pesar de sus ventajas, el uso de inteligencia artificial en el modelado tridimensional presenta limitaciones que deben considerarse dentro de contextos profesionales.
Una de las principales desventajas es la dependencia del prompt o de las referencias visuales. Resultados poco precisos suelen derivarse de descripciones insuficientemente detalladas o imágenes de baja calidad.
Además, el sistema de créditos puede representar una barrera en procesos iterativos, especialmente cuando se requieren múltiples intentos para alcanzar un resultado óptimo.
Otra limitación relevante es la necesidad de ajustes manuales posteriores. Aunque los modelos generados son funcionales, en producción profesional suelen requerir refinamiento adicional en topología, materiales o animación.
Por último, la interpretación algorítmica puede introducir variaciones no deseadas en diseños específicos, lo que evidencia que estas herramientas aún no sustituyen completamente el criterio técnico del modelador.
Conclusiones
La incorporación de inteligencia artificial en los procesos de modelado tridimensional marca una transformación significativa en la producción digital contemporánea. Herramientas como Meshy demuestran que la creación de personajes, tradicionalmente asociada a flujos complejos y prolongados, puede evolucionar hacia dinámicas más ágiles sin comprometer la base técnica necesaria para su integración en entornos profesionales.
A lo largo del proceso experimental, se evidenció que la calidad del resultado está directamente vinculada al nivel de precisión conceptual del usuario. La inteligencia artificial no sustituye el conocimiento especializado, sino que amplifica la capacidad de materializar ideas de forma más eficiente. En este sentido, competencias fundamentales como la comprensión de la anatomía, la topología o el comportamiento de los materiales continúan siendo determinantes dentro del pipeline de producción.
El uso combinado de prompts estructurados y referencias visuales permitió alcanzar niveles de fidelidad significativos en la representación de personajes cinematográficos. Sin embargo, las variaciones observadas en proporciones, detalles faciales o materiales reflejan que estas tecnologías aún requieren supervisión humana para alcanzar estándares de producción avanzados. Esta condición no debe interpretarse como una limitación, sino como una característica inherente a las herramientas en evolución.
En la industria de la animación y el cine digital, la inteligencia artificial ya comienza a integrarse como un recurso complementario dentro de procesos creativos complejos. Estudios como Pixar han demostrado que la innovación tecnológica no busca reemplazar al artista, sino expandir sus posibilidades. La automatización de tareas repetitivas permite que los equipos creativos concentren sus esfuerzos en aspectos narrativos, expresivos y conceptuales, fortaleciendo la calidad artística de los proyectos.
Desde esta perspectiva, herramientas como Meshy pueden entenderse como catalizadores de nuevas metodologías de trabajo. Su utilidad se manifiesta especialmente en etapas de conceptualización, prototipado rápido y generación de activos base, donde la rapidez y la iteración son factores clave. La colaboración entre criterio humano y sistemas inteligentes configura un modelo híbrido que redefine el rol del artista digital, orientándolo hacia la dirección creativa y la supervisión técnica.
En última instancia, el avance de la inteligencia artificial en el modelado tridimensional no representa una sustitución del talento humano, sino una ampliación de su alcance. El futuro del cine digital y la animación dependerá de la capacidad de integrar estas tecnologías de manera consciente, equilibrando eficiencia productiva con sensibilidad artística.
Créditos:
Autor: Diego Alejandro Fernández Rodríguez
Editores: Magister Ingeniero Pinzón – Juan Sebastian Alvarez Rojas
Codigo: COD UCIAG-7
Universidad: Universidad Central
Fuentes
Autodesk. (2023). ¿Qué es el modelado 3D?
https://www.autodesk.com/es/solutions/3d-modeling-software
Blender Foundation. (2024). Manual de Blender.
https://docs.blender.org/manual/es/latest/
Carpenter, J. (Director). (1978). Halloween [Película]. Compass International Pictures.
D5 Render. (2024). What is PBR in computer graphics.
https://www.d5render.com/posts/what-is-pbr-in-computer-graphics
Epic Games. (2024). Trazado de rayos en Unreal Engine.
https://dev.epicgames.com/documentation/es-es/unreal-engine/ray-tracing
Foundry. (2023). Topología en modelado 3D.
https://learn.foundry.com/modo/content/help/pages/modeling/topology.html
Lumion. (2023). Materiales PBR: definición y funcionamiento.
https://lumion.es/materiales-pbr/
Meshy. (2025a). Generador de modelos 3D con inteligencia artificial.
https://www.meshy.ai
Meshy. (2025b). Cómo crear modelos 3D con IA.
https://www.meshy.ai/blog/how-to-make-a-3d-model
Meshy. (2025c). Image to 3D workflow.
https://www.meshy.ai/blog/transform-text-into-ai-images-for-3d-creation
NVIDIA. (2024). ¿Qué es el ray tracing?
https://www.nvidia.com/es-la/geforce/what-is-ray-tracing/
Pixar Animation Studios. (2023). Graphics research library.
https://graphics.pixar.com/library/
Rose, B. (Director). (1992). Candyman [Película]. TriStar Pictures.
Tarantino, Q. (Director). (2003). Kill Bill Vol. 1 [Película]. Miramax Films.
The Foundry. (2023). UV mapping.
https://learn.foundry.com/modo/content/help/pages/uving/uv_mapping.html
Unity Technologies. (2024). Importación de modelos 3D.
https://docs.unity3d.com/es/current/Manual/ImportingModelFiles.html
Warner Bros. (1978). Superman [Película].
Wikipedia. (2024). Subsurface scattering.
https://es.wikipedia.org/wiki/Subsurface_scattering
Wikipedia. (2024). Wireframe model.
https://es.wikipedia.org/wiki/Wireframe







