
Modelado de personajes 3D con Meshy AI: Paso a paso
Introducción
La inteligencia artificial ha transformado de manera radical la industria del diseño digital y el modelado tridimensional. Lo que antes requería equipos especializados, software de alto costo y anos de formación técnica, hoy puede realizarse mediante herramientas accesibles que interpretan instrucciones en lenguaje natural y las convierten en modelos 3D detallados. En este contexto, plataformas como Meshy AI emergen como soluciones innovadoras que democratizan el acceso a la creación de contenido tridimensional de alta calidad (Meshy AI, 2024).
El presente artículo documenta de manera detallada el proceso de creación de cinco personajes 3D de películas clásicas utilizando Meshy AI como herramienta principal. Los personajes seleccionados son: Jack Dawson de Titanic (1997), Jake Sully en su forma Na’vi de Avatar (2009), Brittany de Legally Blonde (2001), El Grinch de How the Grinch Stole Christmas (2000) y Harry Potter de Harry Potter and the Sorcerer’s Stone (2001). Esta selección obedece a la necesidad de trabajar con personajes visualmente diversos —humanos, alienígenas y criaturas— que permitan explorar las capacidades y limitaciones de la herramienta.
La metodología central del ejercicio consiste en el diseño de prompts optimizados —instrucciones textuales estructuradas— en español e inglés, con un límite de 800 caracteres impuesto por la plataforma. Cada prompt incorpora una descripción física detallada del personaje, especificaciones de vestuario y, fundamentalmente, instrucciones precisas para lograr la pose T (T-pose), que es el estándar de referencia en la industria del modelado y la animación 3D (Kerlow, 2004). El artículo analiza los resultados obtenidos, las ventajas y limitaciones de la herramienta, y reflexiona sobre el rol del prompt engineering en los flujos de trabajo modernos de diseño digital.
¿Qué es Meshy AI y como funciona?
Meshy AI es una plataforma de generación de modelos 3D basada en inteligencia artificial, diseñada para facilitar el modelado tridimensional sin necesidad de dominar softwares complejos como Blender o Maya. Permite crear activos de alta calidad en pocos minutos a partir de texto o imágenes (Meshy AI, 2024).
A nivel técnico, funciona mediante modelos de difusión adaptados al entorno 3D, capaces de generar geometría, topología y texturas. Para ello, combina procesamiento de lenguaje natural, redes neuronales y sistemas de texturización, logrando transformar descripciones en modelos tridimensionales completos (Poole et al., 2022).
Tipos de generación disponibles
Meshy AI ofrece cuatro modalidades principales de generación, cada una orientada a diferentes necesidades del usuario:
- Imagen a 3D: Esta modalidad toma una imagen de referencia como entrada y genera un modelo tridimensional basado en ella. Es la opción mas recomendada para la creación de personajes, ya que permite proporcionar una referencia visual exacta del resultado esperado que seria un modelado. En el ejercicio documentado en este articulo, esta fue la modalidad principal utilizada.
- Texto a 3D: Permite generar modelos únicamente a partir de una descripción textual (prompt). Es la modalidad mas flexible pero también la que requiere mayor precisión en la redacción del prompt, ya que el sistema no dispone de referencia visual externa.
- Texto a Imagen: Genera imagenes 2D a partir de descripciones textuales, util como paso previo a la generacion 3D cuando no se dispone de imagen de referencia.
- 3D a Video: Convierte modelos tridimensionales en animaciones o videos, útiles para visualización y presentación de los activos creados.
Flujo general del proceso
El proceso de creación en Meshy AI sigue una secuencia lógica que puede resumirse en las siguientes etapas: ingreso a la plataforma y autenticación, selección de la modalidad de generación, configuración de parámetros, redacción e ingreso del prompt, carga de imagen de referencia (si aplica), generación de la malla 3D, texturización del modelado y exportación o visualización del resultado. Cada una de estas etapas se documenta en detalle en la sección siguiente del presente artículo.
Proceso paso a paso para generar un personaje en 3D
La siguiente guía práctica documenta el proceso completo de creación de un personaje 3D en Meshy AI, basada en el video tutorial ‘Cómo crear un personaje en Meshy AI’ (Tutorial de referencia, 2026). Cada paso se describe con el nivel de detalle necesario para que cualquier usuario pueda replicar el proceso sin conocimientos previos en modelado tridimensional.
Paso 1: Ingreso a la Plataforma
El primer paso consiste en acceder a la plataforma a través de la dirección web meshy.ai. . Se recomienda crear una cuenta gratuita con correo electrónico, ya que esto permite acceder al Espacio de Trabajo personal donde se almacenan todos los modelos generados. La versión gratuita otorga 100 créditos iniciales que se consumen con cada generación. Es importante destacar que la plataforma está disponible en español, lo que facilita la navegación para usuarios hispanohablantes.
Una vez autenticado, el usuario accede al panel principal (Dashboard) donde se presenta la pregunta: “¿Cómo puede ayudarte Meshy hoy?” con las cuatro modalidades de generación disponibles. Para la creación de personajes con referencia de imagen, se debe seleccionar la opción “Imagen a 3D”.
Paso 2: Configuración del Espacio de Trabajo
Al ingresar al Espacio de Trabajo de Imágenes, se presenta una interfaz dividida en tres columnas: el panel izquierdo de configuración, el área central de previsualización del modelo y el panel derecho de historial de generaciones. En el panel izquierdo se encuentran los parámetros configurables que determinan la calidad y las características del modelado generado.
Los parametros mas importantes a configurar son:
- Relación de aspecto: Define la proporción de la imagen de entrada. Para personajes de cuerpo completo se recomienda una relación vertical (retrato).
- Número de imágenes: Determina cuántas variaciones del modelado se generarán en una sola ejecución. Se recomienda generar entre 2 y 4 variaciones para tener opciones de selección.
- Calibración: Ajusta el nivel de adherencia del modelo generado a la imagen de referencia. Un valor alto produce mayor fidelidad pero menor creatividad interpretativa.
- Visión múltiple: Activa la generación de vistas desde múltiples ángulos del personaje, esencial para modelos 3D de uso profesional.
- Pose: Permite especificar la pose base del modelo. Se selecciona “T-Pose” para asegurar que el modelo salga en la posición estándar de modelado.
- Licencia: Define los derechos de uso del modelo generado. La opción gratuita no permite descarga del archivo 3D.
Paso 3: Carga de la Imagen de Referencia y Redacción del Prompt
Este es el paso más crítico de todo el proceso. Se debe cargar la imagen de referencia del personaje haciendo clic en el área de carga de imágenes en el panel izquierdo. La imagen debe mostrar al personaje de cuerpo completo, preferiblemente con fondo blanco o neutro para facilitar la segmentación automática que realiza el sistema.
Simultáneamente, en el campo de texto del panel derecho, se ingresa el prompt en inglés. Se recomienda usar siempre el inglés como idioma del prompt, ya que los modelos de inteligencia artificial que sustentan Meshy AI fueron entrenados predominantemente con datos en este idioma, lo que resulta en una mejor interpretación de las instrucciones y, por ende, en modelos de mayor calidad y fidelidad.
El prompt debe estructurarse siguiendo el orden: descripción física general, vestimenta detallada, instrucciones de pose, especificaciones anatómicas de articulaciones críticas (codos, región de ingle, rodillas) y parámetros de calidad visual. Este orden no es arbitrario: refleja la jerarquía de información que el modelo de IA procesa al interpretar el texto, priorizando primero la silueta general antes de los detalles específicos (Brown et al., 2020).
Paso 4: Generación del Modelo 3D
Una vez configurados todos los parámetros y cargados el prompt y la imagen de referencia, se presiona el botón “Generar”. La plataforma comienza el proceso de generación, que toma aproximadamente entre 60 y 90 segundos dependiendo de la complejidad del personaje y la carga del servidor. Durante este tiempo, se muestra una barra de progreso en la parte inferior del área central.
El motor de Meshy AI realiza en este momento tres procesos paralelos: la segmentación de la imagen de referencia para extraer al personaje del fondo, la inferencia de la geometría tridimensional a partir de la silueta y el prompt, y la construcción inicial de la malla poligonal (mesh) que conformará el modelo 3D. Al finalizar, se presenta el modelo en la vista central en su estado de malla sin textura —lo que en la industria se denomina “modelo gris” o clay render.
Paso 5: Visualización y Verificación de la Malla
Con el modelo generado, el usuario puede rotarlo libremente en el espacio tridimensional usando el mouse para verificar que la pose T sea correcta, que los brazos estén extendidos horizontalmente, que los codos estén completamente rectos y que las rodillas no presenten curvatura. Este es el momento de evaluar si la generación fue exitosa o si es necesario realizar ajustes en el prompt y generar nuevamente.
Meshy AI muestra adicionalmente estadísticas técnicas del modelo generado, incluyendo el número de caras (faces) y vértices (vertices) de la malla. Para modelos de personajes destinados a uso en videojuegos o animación, se recomienda un rango de 200.000 a 500.000 triángulos para equilibrar calidad visual y rendimiento computacional.
Paso 6: Texturización del Modelo
Una vez validada la malla, se procede a la texturización. En el panel izquierdo, se cambia a la sección “Textura” y se selecciona “Entrada de imagen” para que el sistema utilice la imagen de referencia cargada previamente como base para generar los mapas de textura. Se activan las opciones “Eliminar iluminación” y “Generar mapas PBR” (Physically Based Rendering), que permiten obtener mapas de textura de mayor calidad y compatibles con los estándares industriales.
Al presionar el botón “Texturizar”, el sistema aplica colores, materiales y detalles de superficie al modelo tridimensional. Este proceso tarda aproximadamente un minuto adicional. El resultado es un modelado 3D completamente texturizado, con colores y detalles de ropa que se asemejan a la imagen de referencia original. Este modelo puede rotarse y visualizarse desde cualquier ángulo en la plataforma.
Paso 7: Revisión del Resultado y Opciones de Exportación
El resultado final se presenta en el área central con textura completa. El usuario puede comparar el modelo con la imagen de referencia original haciendo clic en el thumbnail de la referencia en el panel izquierdo. Meshy AI también genera automáticamente una versión en escala de grises (sin textura) que puede ser útil para verificar la geometría pura del modelo.
En cuanto a la exportación, la versión gratuita de Meshy AI no permite la descarga directa del archivo 3D en formatos como OBJ, FBX o GLTF. Esta funcionalidad está restringida a los planes de pago. Sin embargo, sí es posible visualizar el modelado en la plataforma, compartir un enlace de visualización 3D y, en algunos casos, usar la API para integraciones con otros sistemas (Meshy AI, 2024).
Video del paso a paso: Generación de personajes en 3D en Meshy AI
Personajes creados
Personaje 1: Jack Dawson
Descripción del Personaje
Jack Dawson es el protagonista masculino de la película Titanic (1997). Se trata de un joven artista estadounidense de clase trabajadora que viaja como polizón en el famoso transatlántico RMS Titanic. Su apariencia refleja la moda de finales del siglo XIX: ropa sencilla pero limpia, cabello castaño desordenado y una mirada azul característica que lo convirtió en un ícono cinematográfico. Su personaje representa la libertad, el romanticismo y la valentía, valores que deben reflejarse también en la representación visual del modelado 3D.
Prompts utilizados
Español
Hombre blanco joven, 20s, complexión atlética delgada, cabello castaño revuelto, ojos azules, piel levemente bronceada. Camisa de lino blanco roto, pantalón de lana azul marino con tirantes colgando, botas de cuero marrón con cordones. POSE T ESTRICTA: de pie erguido, ambos brazos extendidos horizontalmente a 90 grados, palmas hacia abajo. CODOS: completamente rectos, cero doblez, articulación visible en la manga. INGLE: separación anatómica entre piernas, costura interna del pantalón visible, piernas paralelas y juntas. RODILLAS: totalmente rectas, rótula definida visible a través de la tela, sin doblez. Expresión neutra, boca cerrada. Cuerpo completo, fondo blanco liso, fotorrealista, 8K, iluminación de estudio.
Inglés
Young white male, early 20s, slim athletic build, tousled light brown hair, blue eyes, slightly tan skin. Off-white linen shirt loosely tucked into dark navy wool trousers with suspenders, brown leather lace-up boots. STRICT T-POSE: standing upright, both arms extended horizontally at 90 degrees, palms facing down. ELBOWS: fully extended, zero bend, elbow joint clearly visible through sleeve fabric. GROIN: natural anatomical leg separation, inseam visible, legs parallel and close. KNEES: fully straight, kneecap definition visible through fabric, no bend. Neutral expression, mouth closed. Full body, plain white background, photorealistic, 8K, studio lighting.
Resultado obtenido
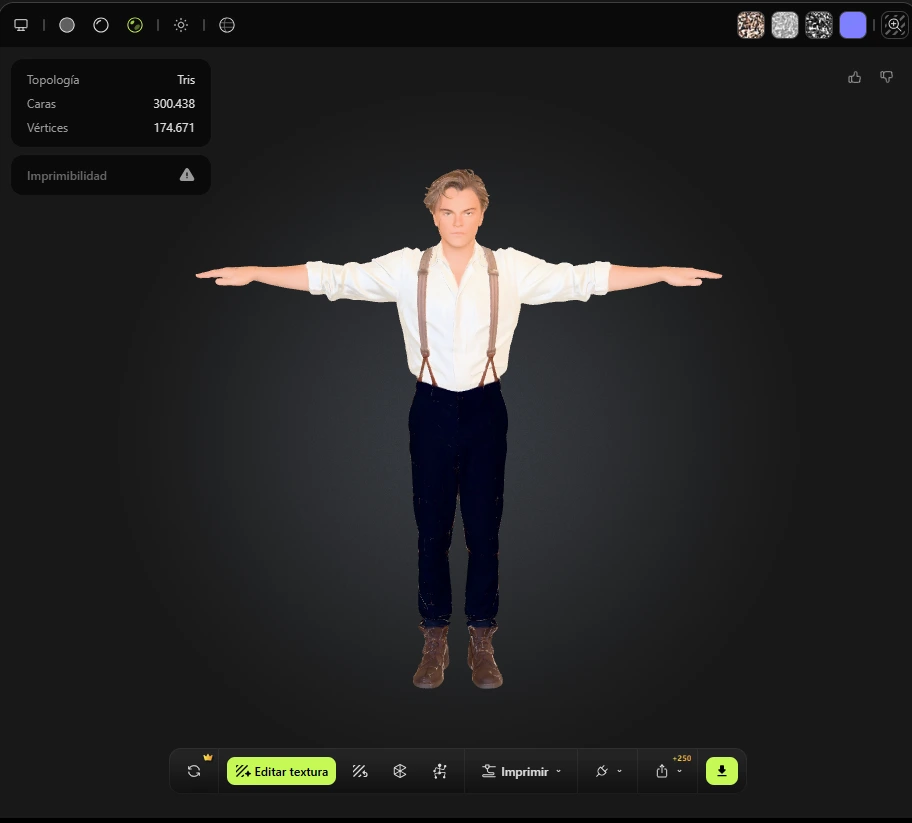
Personaje 2: Jake Sully (Avatar)
Descripción del Personaje
Jake Sully en su forma Na’vi es uno de los personajes más visualmente complejos del cine contemporáneo. Se trata de un humanoide alienígena de aproximadamente tres metros de altura, con piel azul bioluminiscente, ojos felinos de color amarillo verdoso y una cola larga. Los Na’vi son la raza indígena del planeta Pandora en la película Avatar (2009) de James Cameron. Para el modelado 3D, este personaje representa un desafío especial dado que no es humano, por lo que el prompt debe describir con precisión cada característica no convencional: la piel, los ojos, la cola y los elementos tribales de su vestimenta.
Prompts utilizados
Español
Humanoide alienígena alto, piel azul brillante con manchas bioluminiscentes en hombros y mejillas. Ojos grandes amarillo-verdosos con pupilas felinas. Cabello oscuro largo trenzado con plumas y cuentas. Cola larga. Taparrabos Omaticaya en fibras naturales, armadura tribal mínima de hueso en pecho. POSE T ESTRICTA: erguido, brazos extendidos horizontalmente a 90 grados, palmas abajo, dedos ligeramente separados. CODOS: completamente extendidos, cero doblez, articulación prominente visible. INGLE: tela del taparrabos cae natural, separación de piernas clara, piernas paralelas. RODILLAS: totalmente rectas, rótula visible, pies planos. Expresión neutra, boca cerrada. Cuerpo completo, fondo blanco, CGI fotorrealista estilo Avatar, 8K.
Inglés
Tall alien humanoid, bright blue skin with bioluminescent spots on shoulders and cheeks. Large yellow-green feline eyes with vertical pupils. Long dark braided hair with feathers and beads. Long tail. Wearing Omaticaya loincloth in natural fibers, minimal bone tribal chest armor. STRICT T-POSE: standing upright, arms extended horizontally at 90 degrees, palms down, fingers slightly spread. ELBOWS: fully extended, zero bend, anatomically prominent joint clearly visible. GROIN: loincloth falls naturally, clear leg separation, legs parallel. KNEES: fully straight, kneecap structure visible, feet flat on ground. Neutral expression, mouth closed. Full body, plain white background, photorealistic CGI Avatar quality, 8K.
Resultado obtenido
Personaje 3: Brittany ¿Y dónde están las rubias?
Descripción del Personaje
Brittany es un personaje secundario de la película Legally Blonde (2001), conocida en Latinoamérica como ¿Y dónde están las rubias?. Es miembro de la hermandad Delta Nu y encarna el estereotipo de la chica universitaria estadounidense de principios de los 2000: rubia platinada, delgada, con ropa ajustada en tonos rosa pastel y jeans acampanados de tiro bajo. Su vestimenta y apariencia son características de la estética sorority girl que predominó en la cultura pop de esa década, lo que hace que el reto del prompt sea capturar ese estilo con precisión histórica y visual.
Prompts Utilizados
Español
Mujer blanca joven, 20s, complexión delgada, cabello largo liso platinado rubio, ojos azules, piel clara. Maquillaje pulido: brillo labial rosa, cejas definidas. Top crop rosa pastel ajustado, jeans acampanados tiro bajo lavado claro, tenis blancos pequeños. POSE T ESTRICTA: de pie erguida, ambos brazos extendidos horizontalmente a 90 grados, palmas hacia abajo. CODOS: completamente rectos, cero doblez, articulación del codo visible en brazo desnudo. INGLE: jeans tiro bajo, separación anatómica superior del muslo interno visible, piernas paralelas y juntas. RODILLAS: totalmente rectas, rótula visible a través del denim, sin doblez, pies planos. Expresión neutra, boca cerrada. Cuerpo completo, fondo blanco, fotorrealista, 8K, iluminación
Inglés
Young white female, early 20s, slim toned build, long straight platinum blonde hair, blue eyes, fair skin. Polished makeup: nude-pink lip gloss, defined brows. Fitted pastel pink crop top, low-rise light wash flared jeans, small white sneakers. STRICT T-POSE: standing upright, both arms extended horizontally at 90 degrees, palms facing down. ELBOWS: completely straight, zero bend, elbow joint clearly visible on bare arm. GROIN: low-rise jeans, clear anatomical leg separation at upper inner thigh, legs parallel and close. KNEES: fully straight, kneecap contour visible through denim, no bend, feet flat on ground. Neutral expression, mouth closed. Full body, plain white background, photorealistic, 8K, studio lighting.
Resultado obtenido
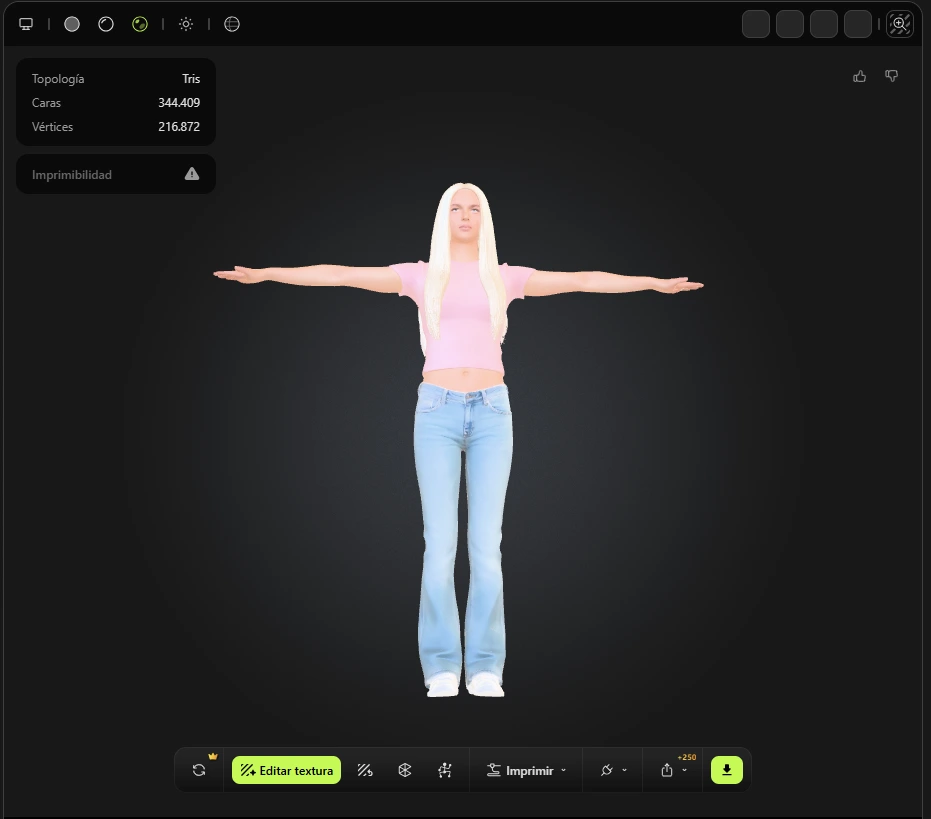
Personaje 4: El Grinch
Descripción del Personaje
El Grinch es uno de los villanos más icónicos de la cultura popular navideña. En la versión cinematográfica del año 2000 dirigida por Ron Howard, Jim Carrey interpreta a esta criatura humanoide completamente cubierta de pelaje verde brillante. El personaje viste el traje de Papá Noel que roba al final de la historia, incluyendo chaqueta roja con ribete blanco, pantalones rojos, cinturón negro con hebilla dorada y botas negras. Para el modelado 3D, el desafío radica en describir la textura del pelaje, los ojos expresivos y el contraste visual entre el verde del cuerpo y el rojo del traje.
Prompts Utilizados
Español
Criatura humanoide alta cubierta de pelaje verde brillante y espeso. Ojos amarillo-verdosos, mirada maliciosa. Dedos largos con uñas alargadas. Traje Papá Noel: chaqueta roja ribete blanco, pantalones rojos, cinturón negro hebilla dorada, botas negras. Pelaje verde en cara, manos y cuello. POSE T ESTRICTA: erguido, brazos extendidos 90 grados, palmas abajo, dedos ligeramente abiertos. CODOS: totalmente rectos, cero doblez, articulación definida en manga roja, arrugas visibles. INGLE: pantalones rojos, separación natural de piernas, hebilla centrada, piernas paralelas. RODILLAS: totalmente rectas, rótula visible a través del pantalón rojo. Boca cerrada. Cuerpo completo, fondo blanco, fotorrealista, 8K, estudio.
Inglés
Tall humanoid covered in thick shaggy bright green fur. Small yellow-green eyes with mischievous squint. Long green fingers with elongated nails. Santa costume: red jacket with white trim, red pants, black belt gold buckle, black boots. Green fur on face, hands and neck. STRICT T-POSE: upright, arms extended at 90 degrees, palms down, fingers slightly spread. ELBOWS: fully straight, zero bend, joint defined within red sleeve, fabric creases at elbow. GROIN: red Santa pants, natural leg separation visible, belt buckle centered, legs parallel. KNEES: fully straight, kneecap visible through red fabric, boots flat on ground. Mouth closed. Full body, plain white background, photorealistic, 8K, studio lighting.
Resultado obtenido
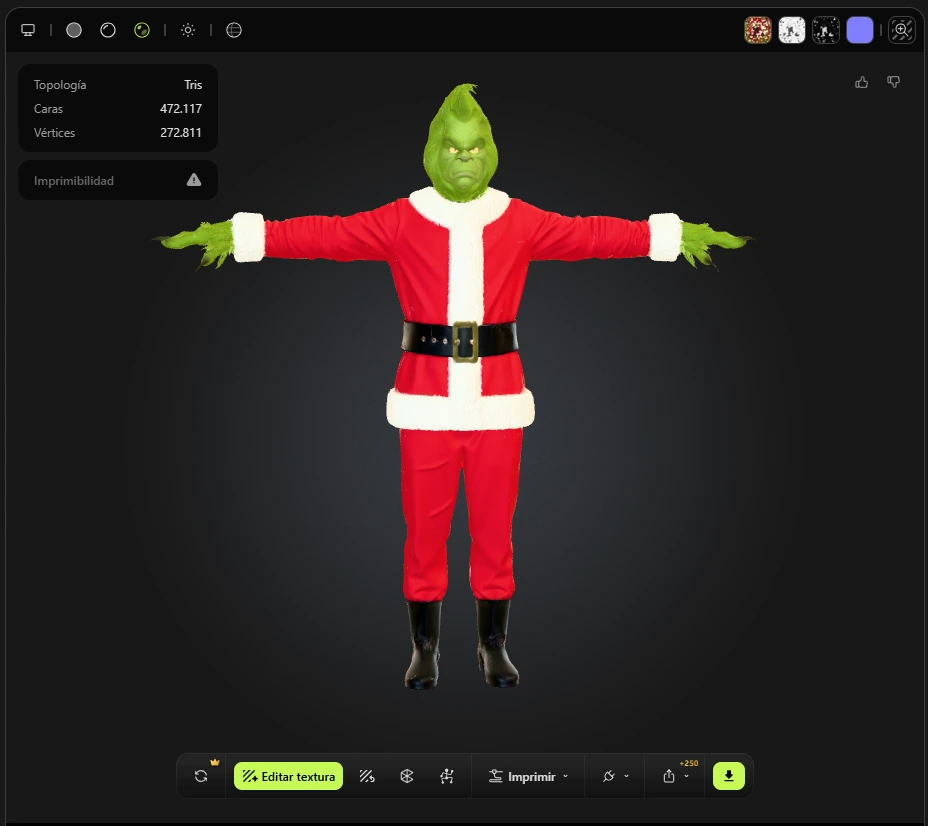
Personaje 5: Harry Potter
Descripción del Personaje
Harry Potter es el protagonista de la saga cinematográfica más exitosa de la década de los 2000, basada en los libros de J.K. Rowling. En la primera película, el personaje es interpretado por Daniel Radcliffe a los 11 años: un niño pequeño de complexión delgada, cabello negro corto y revuelto, gafas redondas metálicas, ojos verdes brillantes y la icónica cicatriz en forma de rayo en la frente. Su uniforme de Hogwarts incluye túnica larga negra, camisa blanca, corbata de rayas, pantalones negros y zapatos Oxford. Para el modelado 3D, es fundamental que el prompt describa con exactitud la edad y talla del personaje, ya que se trata de un niño y no de un adulto.
Prompts Utilizados
Español
Chico blanco, 11 años, complexión pequeña, cabello negro corto revuelto, gafas redondas metálicas, ojos verdes, cicatriz rayo en frente sobre ceja derecha. Uniforme Hogwarts: túnica larga negra, camisa blanca, corbata rayas grises, pantalones negros, zapatos Oxford negros, escudo Gryffindor en pecho. POSE T ESTRICTA: erguido, ambos brazos extendidos a 90 grados, palmas abajo, túnica cayendo naturalmente. CODOS: totalmente rectos, cero doblez, articulación visible donde la manga hace pliegues. INGLE: pantalones negros, separación anatómica de piernas, costura interna definida, piernas paralelas y juntas. RODILLAS: completamente rectas, rótula visible. Expresión neutra, boca cerrada. Cuerpo completo, fondo blanco, fotorrealista, 8K.
Inglés
Young white male, 11 years old, small slim build, messy short black hair, round thin wire-frame glasses, bright green eyes, lightning bolt scar on forehead above right eyebrow. Hogwarts uniform: long black wizard robes, white collared shirt, black and grey striped tie, black trousers, black Oxford shoes, Gryffindor crest on left chest. STRICT T-POSE: standing upright, both arms extended horizontally at 90 degrees, palms down, robes draping naturally. ELBOWS: fully straight, zero bend, elbow joint visible where sleeve creases. GROIN: black trousers, natural anatomical leg separation, inseam clearly defined, legs parallel and close. KNEES: completely straight, kneecap visible through fabric, no bend. Neutral expression, mouth closed. Full body, plain white background, photorealistic, 8K.
Resultado obtenido
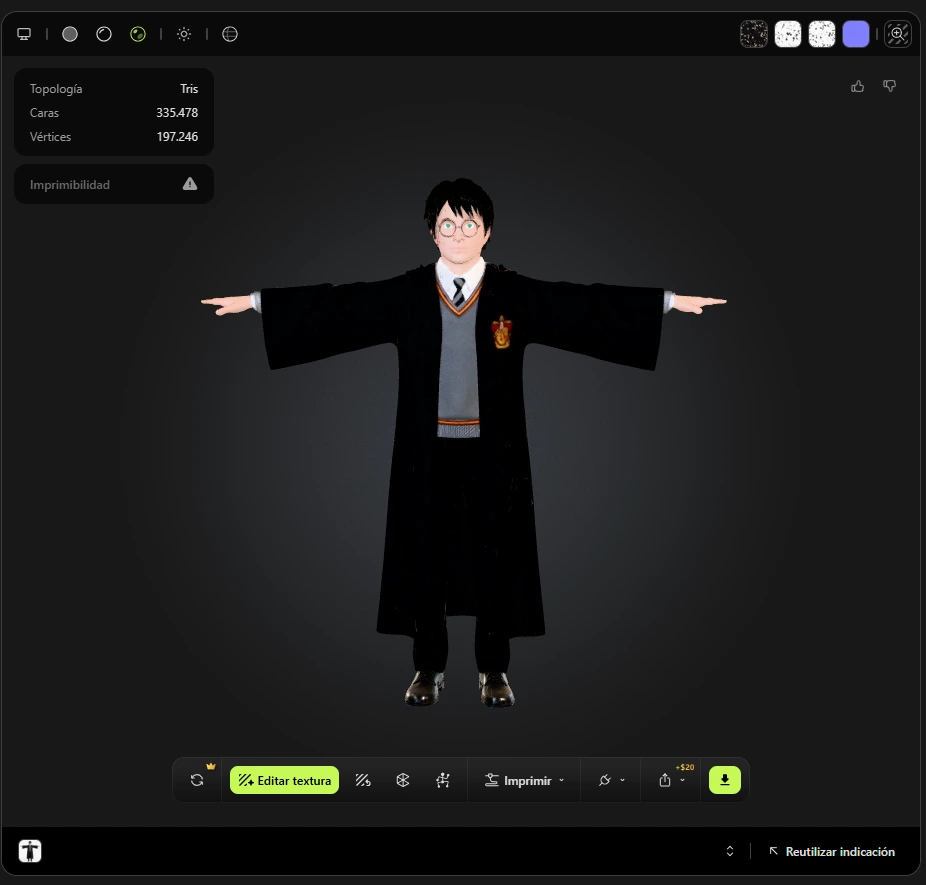
Análisis de prompts para Meshy AI
Estructura General de un Prompt Efectivo
Un prompt efectivo para la generación de personajes 3D en Meshy AI no es simplemente una descripción libre del personaje. Requiere una estructura jerárquica y precisa que guíe al modelo de IA a través de las capas de información que necesita para construir el modelo tridimensional (Oppenlaender, 2022). En el ejercicio documentado, se identificaron cinco componentes fundamentales que todo prompt efectivo para modelado de personajes debe incluir:
Componentes del Prompt
a) Descripción Física General
Este es el primer bloque del prompt y establece la “silueta base” del personaje. Debe incluir género, edad aproximada, complexión corporal, tono de piel, color y tipo de cabello, y color de ojos. Esta información es procesada primero por el modelado de IA y determina la arquitectura general del cuerpo que se va a generar. Por ejemplo: “Young white male, early 20s, slim athletic build, tousled light brown hair, blue eyes”.
b) Descripción de Vestimenta
El segundo bloque detalla la ropa y los accesorios del personaje. Aquí la especificidad es clave: no basta con decir “camisa blanca”, sino que se debe especificar el material (linen shirt), el ajuste (loosely tucked), los accesorios (suspenders) y el calzado (brown leather lace-up boots). Cuantos más detalles se proporcionen en este bloque, mayor será la fidelidad visual del modelo generado.
c) Instrucción de Pose T (T-POSE)
La pose T es el estándar de referencia en la industria del modelado y la animación 3D. En esta posición, el personaje está de pie con los brazos extendidos horizontalmente a 90 grados respecto al torso y las palmas mirando hacia abajo (Kerlow, 2004). Su importancia radica en que: permite un rigging (armado de esqueleto) limpio y sin deformaciones, facilita la aplicación de texturas sin distorsión, es el punto de partida estándar para el proceso de animación y asegura que todas las articulaciones del personaje estén correctamente definidas y accesibles para el animador.
En el prompt, la instrucción de pose T debe escribirse en mayúsculas (“STRICT T-POSE” o “POSE T ESTRICTA”) para que el modelo de IA le asigne máxima prioridad dentro de la instrucción. Esta es una técnica de prompt engineering que consiste en usar mayúsculas para enfatizar instrucciones críticas.
d) Especificaciones Anatómicas de Articulaciones
Este es el bloque más técnico del prompt y el que mayor impacto tiene en la usabilidad del modelo 3D generado. Las articulaciones críticas —codos, región pélvica (ingle) y rodillas— son los puntos donde el modelo es más propenso a generar deformaciones o posturas incorrectas si no se especifican explícitamente. El formato recomendado es:
- ELBOWS / CODOS: Instrucción explícita de que deben estar completamente rectos, sin ningún grado de flexión, con la articulación visible.
- GROIN / UPPER LEGS: Especificación de la separación anatómica natural entre las piernas, la visibilidad de la costura interna del pantalón y el paralelismo de las extremidades.
- KNEES / RODILLAS: Confirmación de que las rodillas deben estar totalmente extendidas, sin curvatura, con la rótula definida a través de la tela.
e) Parámetros de Calidad Visual
El cierre del prompt debe incluir instrucciones sobre el fondo, el nivel de detalle y la iluminación: “plain white background, photorealistic, 8K, studio lighting”. El fondo blanco facilita la segmentación del modelo y la aplicación posterior de texturas. El término photorealistic es fundamental para evitar que el sistema genere resultados con estética de videojuego o animación. 8K referencia la resolución de los mapas de textura deseados. Studio lighting garantiza una iluminación uniforme sin sombras dramáticas que dificulten la texturización.
La T-Pose: Por qué es Fundamental en el Modelado 3D
La pose T no es una convención arbitraria del mundo del diseño digital. Su adopción como estándar de la industria responde a razones técnicas precisas que se relacionan directamente con los procesos de rigging y animación. Cuando un modelo 3D es entregado en pose T, el animador puede:
- Construir el esqueleto (rig) del personaje de manera simétrica y eficiente, ya que los huesos del brazo izquierdo son un espejo exacto de los del brazo derecho.
- Aplicar pesos de influencia (skinning weights) a cada vértice del modelo sin ambigüedad, ya que ninguna articulación está doblada y todos los vértices son claramente asignables a un segmento corporal específico.
- Aplicar mapas UV (UV unwrapping) sin distorsión, ya que la superficie del modelo está completamente desplegada y accesible.
- Realizar modificaciones geométricas posteriores sin riesgo de deformaciones no deseadas en otras partes del modelo.
Por estas razones, la especificación de la pose T en el prompt de Meshy AI no es un simple detalle estético, sino un requerimiento técnico fundamental para la usabilidad profesional del modelo generado.
Ventajas de usar Meshy AI
Rapidez en la Generación
Una de las ventajas más evidentes de Meshy AI es la velocidad de generación. Un modelo 3D de cuerpo completo, completamente texturizado, que en un flujo de trabajo tradicional podría requerir entre 20 y 80 horas de trabajo de un modelador 3D experto, puede generarse en Meshy AI en aproximadamente 2 a 3 minutos. Esta reducción dramática de los tiempos de producción tiene implicaciones directas en los costos y la competitividad de proyectos que requieren gran cantidad de activos 3D, como videojuegos, animaciones o experiencias de realidad virtual.
Automatización del Proceso
Meshy AI automatiza las etapas más técnicas y laboriosas del modelado 3D: la construcción de la malla poligonal, la generación de mapas UV y la aplicación de texturas. Estos procesos, que en software tradicional como Blender requieren dominio técnico especializado, son ejecutados automáticamente por el sistema. Esto libera al usuario para concentrarse en las decisiones creativas y de diseño, en lugar de en los aspectos técnicos de la producción (Goodfellow et al., 2016).
Accesibilidad
La plataforma no requiere instalación de software, hardware especializado ni conocimientos de modelado 3D tradicional. Solo se necesita un navegador web y una conexión a internet. Esto democratiza el acceso al diseño tridimensional, permitiendo que estudiantes, emprendedores, educadores y creadores de contenido sin formación técnica en 3D puedan producir activos de calidad aceptable para sus proyectos.
Calidad Visual
Los modelos generados por Meshy AI presentan un nivel de detalle y calidad de textura que, para muchos casos de uso —prototipado rápido, visualización conceptual, contenido educativo, redes sociales— es completamente suficiente. La plataforma soporta mapas PBR (Physically Based Rendering), lo que significa que los modelos se comportan de manera realista ante diferentes condiciones de iluminación en los motores de render modernos.
Desventajas y limitaciones de usar Meshy AI
La Versión Gratuita NO Permite Descargar Modelos
Esta es, sin duda, la limitación más significativa de Meshy AI para usuarios que no cuentan con suscripción de pago. La versión gratuita permite generar y visualizar modelos 3D en la plataforma, pero NO permite exportar ni descargar los archivos en formatos profesionales como OBJ, FBX, GLTF o STL. Para acceder a la descarga de modelos, es necesario adquirir un plan de pago, cuyo costo varía según el nivel de acceso requerido. Esta restricción limita significativamente la utilidad práctica de la herramienta para proyectos que requieren integrar los modelos en otras plataformas o motores de juego.
Limite de Créditos
La versión gratuita otorga 200 créditos iniciales. Cada generación de modelo consume entre 15 y 20 créditos dependiendo de la complejidad y los parámetros seleccionados. Una vez agotados los créditos gratuitos, el usuario debe esperar al período de reposición mensual o adquirir créditos adicionales mediante pago.
Limitaciones en Precisión y Control
A pesar de la calidad general de los modelos generados, Meshy AI presenta limitaciones significativas en cuanto al control fino de detalles específicos. Elementos como expresiones faciales sutiles, detalles de maquillaje, accesorios pequeños (aretes, anillos, insignias), texturas de cabello de alta fidelidad y deformaciones precisas de telas son áreas donde el sistema generativo aún no alcanza los estándares de un modelador humano experto. Adicionalmente, la plataforma no garantiza la reproducción exacta de rasgos faciales de personas reales, lo que limita su uso para personajes que requieren un parecido fotográfico específico con actores reales.
Dependencia de Prompts Bien Estructurados
La calidad del modelo generado es directamente proporcional a la calidad del prompt ingresado. Un prompt vago, mal estructurado o con instrucciones contradictorias produce modelados de baja calidad, con articulaciones incorrectas, texturas incoherentes o proporciones anatómicas erróneas. Esto significa que Meshy AI no es una herramienta de “un clic” para la creación de modelos profesionales, sino que requiere conocimiento de prompt engineering —una habilidad que demanda práctica y comprensión del comportamiento de los modelos de IA generativa (Oppenlaender, 2022).
Filtros de Contenido y Propiedad Intelectual
Como se evidenció durante el desarrollo de este ejercicio práctico, Meshy AI cuenta con filtros automáticos de contenido que pueden bloquear la generación de modelos basados en personajes de franquicias protegidas por derechos de autor. El uso de nombres propios de personajes como “Harry Potter” o términos asociados como “Hogwarts” puede activar estos filtros. La estrategia para superar esta limitación consiste en describir al personaje por sus características físicas y de vestuario, evitando referencias directas a la propiedad intelectual. Adicionalmente, algunos términos anatómicos como “groin” pueden activar filtros de contenido inapropiado, aun cuando se usen en contextos técnicos de modelado 3D.
Conclusiones
El ejercicio de creación de cinco personajes 3D de películas clásicas mediante Meshy AI ha permitido extraer conclusiones relevantes sobre el estado actual de la inteligencia artificial aplicada al modelado tridimensional, el rol del prompt engineering como habilidad profesional emergente y las implicaciones prácticas para flujos de trabajo de diseño digital.
En primer lugar, Meshy AI demuestra que la democratización del modelado 3D es una realidad tecnológica ya disponible. Lo que antes era territorio exclusivo de especialistas con años de formación en software como Maya o 3ds Max, hoy puede ser abordado por cualquier usuario con acceso a internet y la habilidad de redactar instrucciones precisas en inglés. Esta transformación tiene implicaciones directas en industrias como el entretenimiento, la educación, el comercio electrónico y el diseño de productos (Schwab, 2017).
En segundo lugar, el prompt engineering emerge como una competencia profesional de alta relevancia en el contexto de la inteligencia artificial generativa. La calidad de los modelos obtenidos en este ejercicio es directamente proporcional a la precisión, estructura y vocabulario técnico de los prompts utilizados. La diferencia entre un prompt genérico y uno bien estructurado —con descripción física detallada, vestimenta específica, instrucción de pose T en mayúsculas y especificaciones anatómicas de articulaciones críticas— puede significar la diferencia entre un modelado inutilizable y uno listo para integrarse en un flujo de trabajo de producción 3D (Brown et al., 2020).
En tercer lugar, el ejercicio evidencia que las herramientas de IA generativa no reemplazan completamente al modelador 3D humano, sino que transforman su rol. El experto en 3D del futuro no será quien domine los atajos de teclado de Blender, sino quien comprenda las capacidades y limitaciones de los sistemas generativos, pueda diseñar prompts efectivos y tenga el criterio para refinar y mejorar los resultados de la IA en software especializado. Esta sinergia entre inteligencia artificial y experiencia humana es el paradigma que define la producción digital contemporánea.
Créditos
Autor: – Stephany Valentina Saray Gutierrez
Editor: Magister Ingeniero Carlos Iván Pinzón Romero, Sebastián Hernández Pineda
Código: UCIAG-9
Universidad: Universidad Central
Fuentes
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., ... Amodei, D. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877-1901.
Columbus, C. (Dir.). (2001). Harry Potter and the Sorcerer's Stone [Pelicula]. Warner Bros. Pictures.
Cameron, J. (Dir.). (1997). Titanic [Pelicula]. Paramount Pictures; 20th Century Fox.
Cameron, J. (Dir.). (2009). Avatar [Pelicula]. 20th Century Fox.
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT Press.
Howard, R. (Dir.). (2000). How the Grinch Stole Christmas [Pelicula]. Universal Pictures.
Kerlow, I. V. (2004). The art of 3D computer animation and effects (3a ed.). John Wiley & Sons.
Luketic, R. (Dir.). (2001). Legally Blonde [Pelicula]. Metro-Goldwyn-Mayer Pictures.
Meshy AI. (2024). Meshy AI: 3D AI toolkit for creators. https://www.meshy.ai
Oppenlaender, J. (2022). A taxonomy of prompt modifiers for text-to-image generation. arXiv preprint arXiv:2204.13988.
Poole, B., Jain, A., Barron, J. T., & Mildenhall, B. (2022). DreamFusion: Text-to-3D using 2D diffusion. arXiv preprint arXiv:2209.14988.
Saray Gutiérrez, S. V. (2026). Cómo crear un personaje en 3D
en Meshy AI [Video tutorial]. Archivo personal.
Saray Gutiérrez, S. V. (2026). Jack Dawson — resultado
modelo 3D [Captura de pantalla de Meshy AI]. Archivo personal.
Saray Gutiérrez, S. V. (2026). Jake Sully Na'vi — resultado
modelo 3D [Captura de pantalla de Meshy AI]. Archivo personal.
Saray Gutiérrez, S. V. (2026). Brittany — resultado
modelo 3D [Captura de pantalla de Meshy AI]. Archivo personal
Saray Gutiérrez, S. V. (2026). El Grinch — resultado
modelo 3D [Captura de pantalla de Meshy AI]. Archivo personal.
Saray Gutiérrez, S. V. (2026). Harry Potter — resultado
modelo 3D [Captura de pantalla de Meshy AI]. Archivo personal.
Saray Gutiérrez, S. V. (2026). Jack Dawson — resultado
modelo 3D en Meshy AI [Grabación de pantalla]. Archivo personal.
Saray Gutiérrez, S. V. (2026). Jake Sully Na'vi — resultado
modelo 3D en Meshy AI [Grabación de pantalla]. Archivo personal.
Saray Gutiérrez, S. V. (2026). Brittany — resultado
modelo 3D en Meshy AI [Grabación de pantalla]. Archivo personal.
Saray Gutiérrez, S. V. (2026). El Grinch — resultado
modelo 3D en Meshy AI [Grabación de pantalla]. Archivo personal.
Saray Gutiérrez, S. V. (2026). Harry Potter — resultado modelo 3D en Meshy AI [Grabación de pantalla]. Archivo personal.
Schwab, K. (2017). The fourth industrial revolution. Crown Business.







